Keras 深度学习框架使用总结
概述
神经网络在 2012 年后被认为是机器学习领域最受关注的技术,而在神经网络的技术中,深度卷积神经网络已经成为所有计算机视觉任务的首选算法。深度学习利用在计算机视觉上的两个关键思想:卷积神经网络和反向传播,并在数据的学习上,通过渐进的、逐层的方式形成越来越复杂的表示,并对中间的渐进表示共同进行学习。
深度学习的框架包括TensorFlow、PyTorch和 Keras等,其中 JAX、TensorFlow和 PyTorch可以作为 Keras 的 后端(backend) 来进行张量处理、求微分等低层次的运算。本文就 Keras 的实践以及深度学习的一些理论进行总结。
参考 《Deep Learning with Python》 By【美】弗朗索瓦·肖莱
参考 《Advanced Deep Learning with Python》By【保加利亚】伊凡·瓦西列夫
神经网络的数学基础
参考 《DLP》
随机变量和概率分布
通常情况下,神经网络产生一些输出概率分布 $ Q(x) $,在训练中将其与目标分布 $ P(x) $ 进行比较。可以用交叉熵来定义两个分布的距离:
$$ H(P, Q) = -\displaystyle\sum_{i=1}^n P(X=x_i)logQ(X=x_i)$$
交叉熵损失定义为:
$$ Loss = - \displaystyle\sum_{i=1}^n y_ilog{x_i} $$
其中,$ y_i $ 是训练标签值,$ x_i $ 是预测值。
安装及初步使用
安装依赖(可选)
- 如果主机上配备有
GPU,确保驱动正常工作。如果没有 NVIDIA 的 GPU,而是使用 Intel 的集成显卡,需要下载oneAPI计算平台和oneDNN深度学习加速库。1
sudo apt-get install libdnnl2 libdnnl-dev
如果使用树梅派等平台,可以安装 GPU 加速库(OpenCL和OpenCV),参考树莓派5 gpu 加速。
安装
BLAS线性代数库:1
sudo apt-get install libopenblas-dev liblapack-dev
安装 Python 科学计算套件:
Numpy、Scipy和matplotlib1
sudo apt-get install python3-numpy python3-scipy python3-matplotlib
安装
HDF5,用于将Keras模型快速高效地保存到磁盘:1
sudo apt-get install python3-h5py python3-h5py-serial
安装
CUDA:
参考 [CUDA Tutorial] 。
安装 keras
新建虚拟环境并激活
1
2
3python3 -m venv venv
source venv/bin/activate
(venv) $安装后端(默认使用
TensorFlow):1
(venv) $ pip3 install tensorflow
在
~/.keras/keras.json中可以修改使用的后端类型。安装
keras:1
(venv) $ pip3 install keras
初步使用
1 | import keras |
使用 MNIST 数据集,它是机器学习领域的一个经典数据库,用于手写数字的自动识别(最先用于邮政业务中的邮编识别)。
1 | from keras.datasets import mnist |
如果没有下载 MNIST,上述代码会自动将其下载到 ~/.keras/datasets/ 目录中。
架构
软件栈和硬件栈
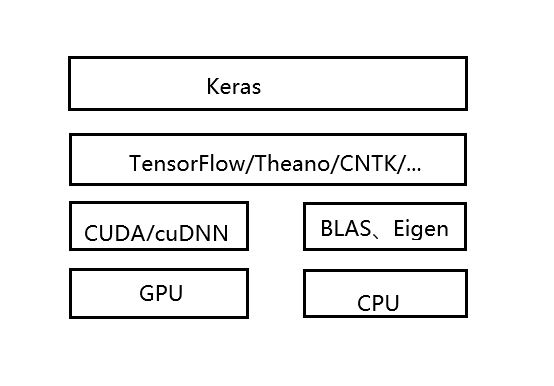
Keras 具有的特性:
- 相同的代码可以无缝切换到不同的后端,也就可以在 CPU 和 GPU 上无缝切换运行。
- 用户友好 API
- 支持任意网络架构
用户API
激活器
如果没有
relu这样的激活函数(非线性函数),Dense层只包含线性运算,这样就只能学习输入数据的线性变换(仿射变换)。这种所有线性变换组成的假设空间非常有限,无法利用多个多个表示层的优势,因为多个线性层堆叠实现的仍然是线性运算。
优化器
损失函数
最常见的机器学习任务:二分类问题、多分类问题和标量回归问题 所使用的损失函数是不同的。标量回归问题的常用损失函数是 均方误差(MSE)。
同样,回归问题的评估指标与分类问题不同,常见的回归指标是平均绝对误差(MAE)。
机器学习
机器学习的分支很复杂,大致分为监督学习、非监督学习、自监督学习和强化学习。
监督学习
二分类问题、多分类问题和标量回归问题都是监督学习(supervised learning)的例子。 监督学习的目标是学习训练输入和训练目标之间的关系,其中训练目标是由人工标注的正确答案。
监督学习的其他变体:
- 序列生成
- 语法树预测
- 目标检测
- 图像分割
无监督学习
无监督学习是指在没有目标的情况下寻找输入数据的变换,其目的在于数据可视化、数据压缩、数据去噪或更好地理解数据中的相关性。
降维(dimensionality)和聚类(clustering)都是众所周知的无监督学习方法。
对于没有标签的数据,聚类(clustering)算法可以将样本数据分为不同的数据簇。
自监督学习
强化学习
评估
过拟合问题
泛化
数据集:训练集、验证集和测试集。
卷积神经网络
卷积层和密集连接层的区别在于,
Dense层从输入特征空间中学到的是全局模式,而卷积层学到的是局部模式。
卷积神经网络的两个重要性质:平移不变形和模式的空间层次结构。
卷积运算
深度神经网络学到的表示的一个重要普遍特征:随着层数的加深,层所提取的特征变得越来越抽象。更高的层激活包含关于特定输入的信息越来越少,而关于目标的信息越来越多。深度神经网络可以有效地作为
信息蒸馏管道,输入原始数据,反复对其进行变换,将无关信息过滤掉,并放大和细化有用的信息。