S32K芯片CPU核性能优化方法总结
概述
MCU 是随着大规模集成电路的出现及其发展,将 CPU 核、存储器、定时器以及各种输入输出模块(外设)通过总线互联并集成到一起的微型计算机。MCU 的性能也随着半导体工业的发展越来越强大,其应用场景也越来越广泛。对于开发者来说,在一些特殊应用场景中需要最大程度地发挥 MCU 中 CPU 核的性能,这就需要开发者对所用 MCU 的架构、总线及各模块特性等有深入的了解。本文以 NXP 的 S32K1XX/S32K3XX 系列 MCU为例, 并参考一些资料对此进行了总结。
架构和存储器映射
S32K1xx(以S32K14x为例)的架构: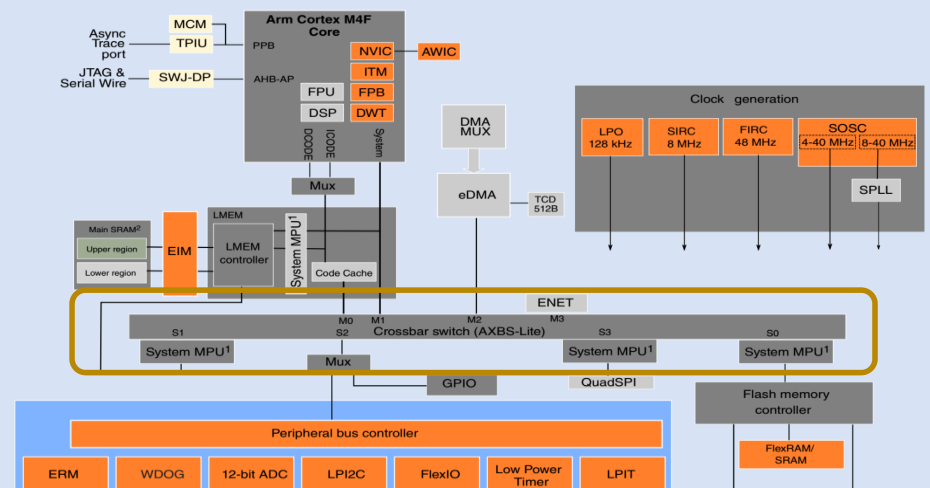
S32K3xx(以S32K312为例)的架构: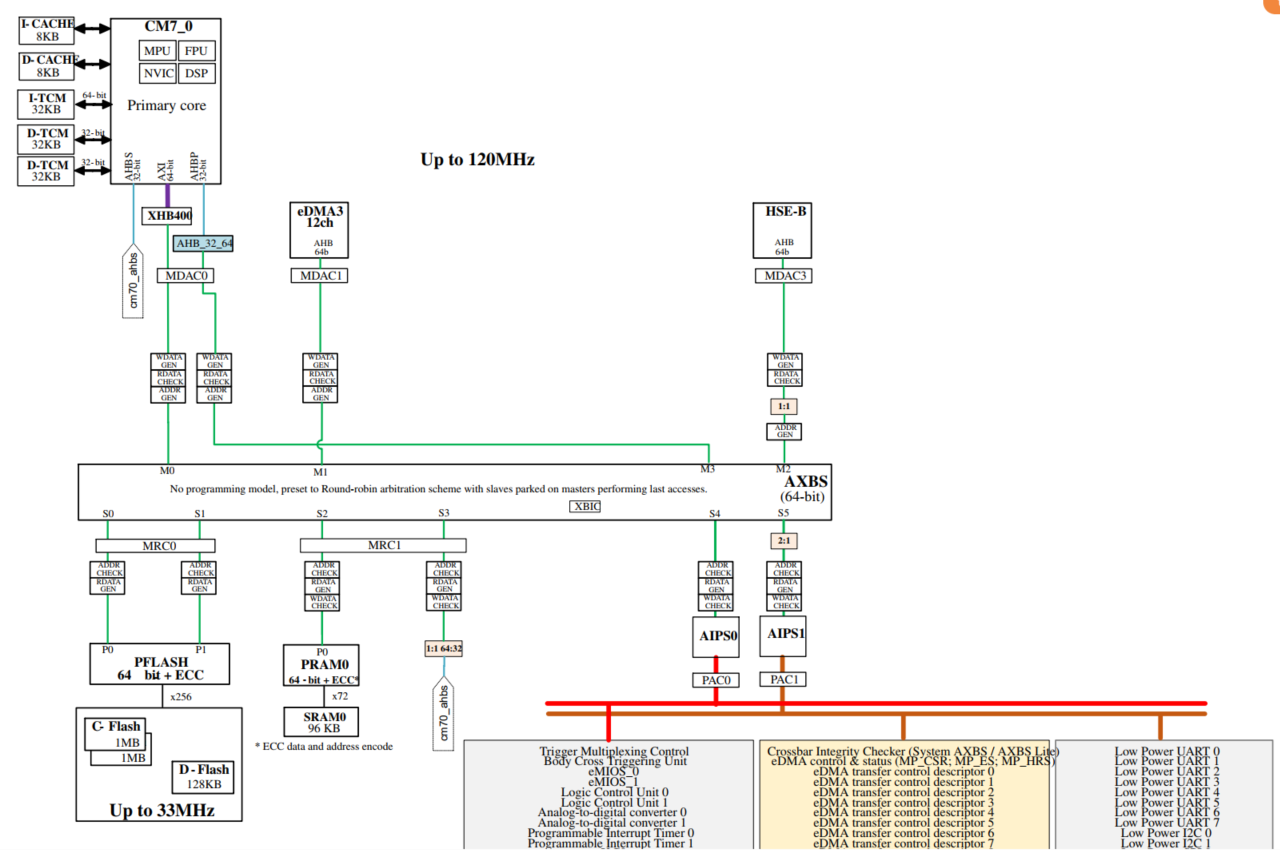
S32K 系列内核的存储器映射,可以概括如下: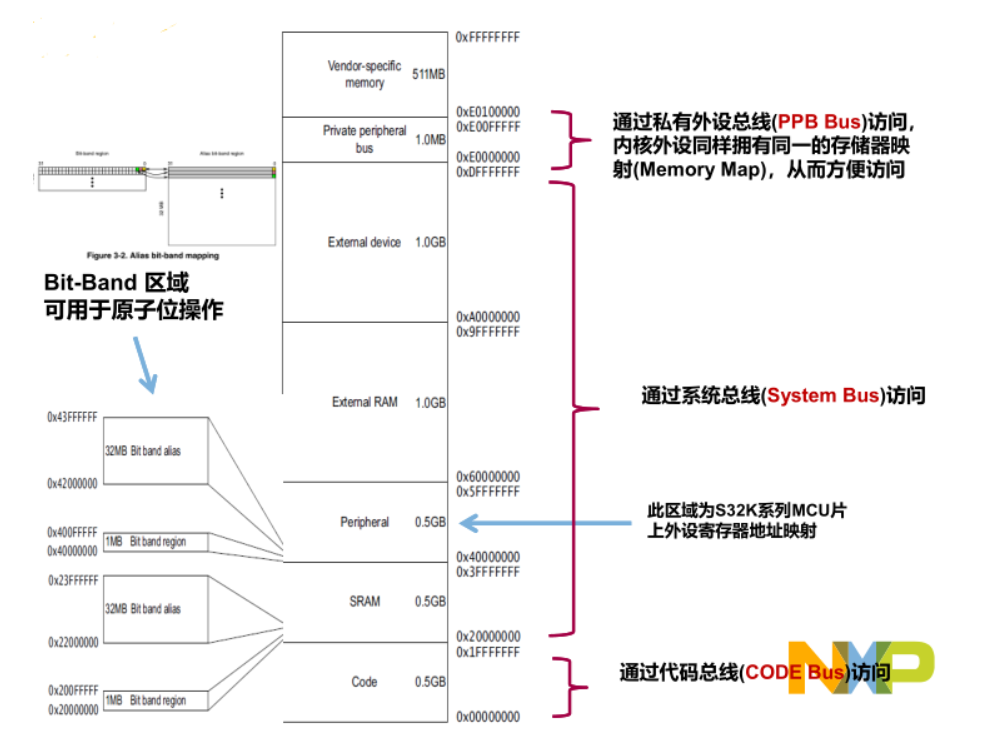
图中的 PPB 又可以分为内部 PPB和外部 PPB,前者主要用来访问 ITM/DWT/PFB/MPU/NVIC,后者主要用来访问 ETM/CTI。
时钟频率
S32K1XX MCU 使用 ARM 的 Cortex M0+ (如 S32K118 和 S32K116)和 Cortex M4F (如 S32K14X)核,主频率可以达到最高 48MHZ 和 112MHZ (HSRUN)模式。S32K3 MCU使用 ARM 的 Cortex M7 核(哈佛架构 + 6级超标量流水线 + 分支预测),主频可以达到 120MHZ-240 MHZ。
但仅仅通过调整 PLL 或者 FLL 产生 CPU 核和内部总线的最高时钟频率就能获得最高性能吗?如果对于计算密集型且不需要考虑 cache 的应用,大概是正确的;但对于大部分应用来说,这样做是不够的。很多应用的性能受到存储、cache、浮点计算、IO等的极大影响,另外我们还要考虑编译器优化、程序链接等软件层面的影响。综合考虑各种软硬方面,开发者才能最大程度地发挥 CPU 核的最大性能。
指令和数据 Cache
从前面的 S32K14x MCU 结构图中我们可以看到 Code Bus 上有 4KB 的指令和数据 Cache,注意这里的 Cache 不在 Cortex M4核的内部,但即使如此,Cache 的使用仍然可以很好地改善 Flash/SRAM 密集型应用的性能。S32K14x 的 cache 需要在 MCU 启动时打开,具体为配置 LMEM->PCCCR 寄存器来使能。
S32K3XX MCU 使用 ARM Cortex-M7 核,该核内也包含了 L1/L2 指令和数据 cache。核内的 cahe 与 D-Cache/I-Cache 的配置可以通过 SCTLR 寄存器来完成。
TCM
从前面 S32K3 系列的架构图中我们可以看到,核对 TCM 的访问不通过 Cache。那么 TCM 和 Cache 的区别在那里呢?
我们可以从设计目的和使用方式方面来区分,TCM 是专门设计用于处理器内部的高速存储器,包括I-TCM代码区和D-TCM数据区,可以存放最常用的代码和数据,用于提高系统的性能。Cache 用于存储最近访问的数据,来减少对外部存储器的访问次数,并提高系统性能;但 Cache 依赖于局部性原理,如果软件设计不是 Cache 友好的,那么就会频繁地发生 Cache 命中失败而访问外部存储器,性能提升受到打折。
另一个区别是,TCM 是处理器内部的存储器,Cache 需要外部存储器的支持,且需要使用特殊的硬件逻辑来管理缓存。
Flash 的工作频率
Flash 的指令和数据预取
编译器优化
内存段的布局
使用硬件 FPU
由于目前主流的 ARM 芯片都自带VFP或者NEON等浮点处理单元(FPU),所以对硬浮点的需求就更加强烈。Linux 的浮点处理可以采用完全软浮点,也可以采用与软浮点兼容,但是使用 FPU 硬件的softfp,以及完全硬浮点。具体的ABI(Application Binary Interface,应
用程序二进制接口)通过-mfloat-abi= 参数指定,3 种情况下的参数分别是-mfloat-abi=soft/softfp/hard。
softfp 使用了硬件的 FPU,但是函数的参数仍然使用整型寄存器来传递,hard 完全硬浮点则直接使用 FPU 的寄存器传递参数。
在启用 FPU 的前提下,编译器在做激进的优化时,会使用浮点寄存器来进行整型数据的拷贝等操作,具体的话,会使用 vstr.64 和 vldr.64 浮点指令。