CUDA Tutorial
概述
CUDA 是专门为提高并行程序效率而开发的计算架构。它提供了对编程人员友好的编程模型,并支持多种高级编程语言(如 C/C++、Fortran、Python、Java)或者 OpenACC。
参考 CUDA C++ Programming Guide。
参考 CUDA C++ Best Practices Guide。
参考 《CUDA By Example : An introduction to General-Purpose GPU Programming》 By Jason Sanders & Edward Kandrot.
开发环境和工具包
查看显卡型号:
$ ubuntu-drivers devices
在CUDA-GPUS 官网 查询该型号显卡是否支持 GPU 计算。
安装驱动:$ sudo apt-get install nvidia-driver-<xxx>
注意在 Linux 平台要禁用 nouveau 驱动,避免和 NVIDIA 驱动冲突。
查看安装后的显卡驱动版本(以及支持的 CUDA 版本):$ nvidia-smi
安装 CUDA(Ubuntu 平台已经对 CUDA 进行了打包) :
$ sudo apt-get install nvidia-cuda-toolkit
或者 参考CUDA 官网安装方法
cmake 支持,参考:使用 CMake 构建跨平台 CUDA 应用程序。
架构
GPU 在某些应用上的性能为什么比在 CPU 上更将大?GPU 的架构和 CPU 的架构有什么不同呢?
相比而言,GPU 更加注重并行计算。尽管 CPU 被设计成擅长以尽可能快的速度执行线程,并且可以并行执行几十个这样的线程,但 GPU 被设计成擅长并行执行数千个(甚至更多)的线程(将较慢的单线程的性能进行分摊,以获得更大的吞吐量)。
另外在硬件设计上,GPU 的晶体管更多的用于数据处理(data processing)而不是数据缓存(data caching)和控制(flow control)。GPU 和 CPU 在芯片资源上的分布如下图所示:
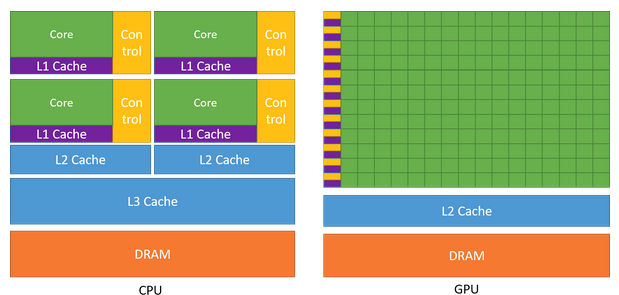
GPU 可以通过计算来隐藏存储器访问延迟,而不是依赖于大量数据缓存和复杂的流控制来避免过长的存储器访问延迟(这两者在晶体管方面都是昂贵的)。
通常,对于具有高度并行性的应用,在 GPU 上比在 CPU 上更能发掘它的并行潜能。
无论是 CPU 还是 GPU,目前基本上都是多核的,这使得并行计算变得越来越重要。但早期的 GPU 计算使用起来非常的复杂,它受限于图形 API 的编程模型(例如 OpenGL 和 DirectX),因为它是和 GPU 交互的唯一方式。
后来,NVIDIA 在其GeForce 8800 GTX产品中首次使用 CUDA 架构,CUDA 架构专门为 GPU 计算设计了一个全新的模块,目的是减轻早期 CPU 计算中存在的一些限制。
CUDA 架构包含了一个统一的着色器流水线,使得执行通用计算的程序能够对芯片上的每个 ALU (算术逻辑单元)进行排列,而且这些 ALU 满足 IEEE 单精度浮点运算,并可以使用一个裁减后的指令集进行通用计算。GPU 上的执行单元既能任意地读写内存,还可以访问由软件管理的缓冲,也称为共享内存(注意与 IPC 机制区分)。
NVIDIA 不仅仅使用 CUDA 架构的硬件来提供通用计算和图形功能,还在软件层面开发了面向 GPU 的高级语言的编译器(如 CUDA C)。CUDA C 在 C 语言的基础上增加了一小部分关键字。另外,NVIDIA 还提供了专门的硬件驱动程序来发挥 CUDA 架构的大规模计算功能。这些都使得用户既不需要了解 OpenGL或 DirectX图形编程框架,也不需要将通用问题伪装成图形计算问题。
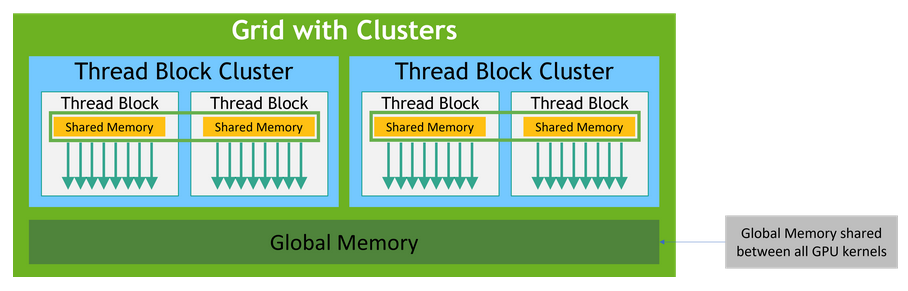
CUDA C 提供了三个主要的抽象:线程块的层次结构、共享内存和屏障同步(barrier synchronization )。这些抽象提供了细粒度的数据级并行和线程级并行,并嵌套在粗粒度的数据级并行和任务级并行中。用户需要将其要解决的问题划分成子问题,这些子问题可以独立并行地被线程块执行,子问题中更加细粒度的交互可以由块中的线程来完成。
这样分解(block 和 block threads )使得解决子问题的线程可以相互交互,也可以保持一种可扩展性。线程块的具体调度由运行时系统完成,而不需要用户关心,也就是说同样的程序可以运行在不同档次的 GPU 上而自动获得不同的性能。
编程模型
核函数
CUDA C++ 是如何描述并行任务的?CUDA C++ 对 C++ 进行了扩展,使得用户可以定义 核函数。核函数 与 一般的 C++ 函数不同之处在于:它可以被 N 个 CUDA 线程 并行执行 N 次。
核函数 需要使用__global__ 声明标识符,当调用核函数时需要使用语言扩展符号 <<<...>>>指定线程组。每个执行核函数的线程都会指定一个单独的 线程ID,并可以在核函数中通过变量threadIdx访问。一个简单例子如下:
1 | __global__ void add(float* A, float* B, float* C) { |
线程块
线程块中的线程可以在逻辑上被组织成一维结构、二维结构和三维结构;同样地,线程块中也可以被组织成单维或多维结构的线程格(Grid)。在一个线程块中的线程的个数是有限制的,可以使用cudaDeviceProp结构中的maxThreadPerBlock成员变量来获得该值(对于当前的 GPU,该值为1024)。
在<<<…>>>中指定线程格和线程块结构时,可以使用int或者dim3类型,使用int就默认指示其结构是一维的。每个块都有一个单独的块 ID,可以使用变量blockIdx访问。每个块的度(可以理解为块的长度和宽度)可以使用变量blockDim访问。线程格的度可以使用gridDim变量访问。
修改上节中的例子,使用二维结构的线程格和二维结构的线程块:
1 | __global__ void add(float A[N][N], float B[N][N], float C[N][N]) { |
所有线程块并行执行,并且执行顺序是任意的,也就是线程块之间不能存在逻辑上或者数据上的相互依赖。每个线程块中的线程虽然也是并行的,但可以访问共享内存(使用__shared__声明标示符),并可以使用__syncthreads() 函数进行同步。
内存
每个线程有私有的本地存储。每个线程块有共享内存,该块中的每个线程都可以访问。另外,所有的线程都可以访问全局内存。另外,还有两种只读内存:常量内存(constant memory)和纹理内存(texture memory),它们可以被所有线程访问。全局内存、常量内存和纹理内存空间对不同的内存使用场景进行了优化,因此恰当地使用合适的内存空间可以显著提供程序的内存性能。