Linux Kernel Introduction
概述
Linux kernel 是开源的单内核(Monolithic Kernel)、模块化和多任务的类Unix操作系统。
在本系列文章中,使用 “Linux” 均代指 “Linux 内核”,如果要指代像 Ubuntu 这样的 Linux 发行版系统,我们使用 “GNU/Linux”。
参考 Linux Kernel - wikipedia
参考《Understanding the Linux Kernel, Third Edition》 By Daniel P. Bovet & Marco Cesati.
参考 linux-insides - By 0xax | Linux内核揭秘-中文版。
参考 kernel teaching
参考 《Linux内核驱动开发详解》By 宋宝华
Unix 渊源
Unix 系统最初在 1969 年诞生于贝尔实验室。Unix 衍生出了很多变种,例如 OpenBSD等,它的很多设计理念也深刻影响了 GNU/Linux(准确来说,主要影响的是内核上层的应用程序和环境) 。更重要的是,Unix有着开放源码和同僚复审的传统,这种理念产生的优势被 Linux 充分的发挥和利用。关于这个主题,可以阅读经典的《The Art of UNIX Programming》 (在 Unix编程艺术笔记 中有一些摘要总结)。
Linux 的成长伴随着互联网的崛起,这就使得它与 Unix 在开发模式上有些不同。Linux 几乎是通过来源于”网络部落“的一些“松散”的开发者贡献给世界的,但它现在已经变得十分强大。《大教堂与集市》一书中有详细和精彩的描述。
乐趣是一个符号,意味着效能、效率和高产。 —— TAOUP
接口
内核-用户 API
内核-用户 ABI
当前针对在不同的 GNU/Linux系统间保持应用和二进制兼容的标准是 LSB(Linux Standard Base)。LSB 中和内核相关的标准包括:General ABI、System V ABI、ELF和Processor Specific ABI。其中,和处理器相关的 ABI 定义了在函数调用时如何传递系统调用号及其他参数(例如,使用寄存器还是栈,以及使用哪些寄存器)。
系统调用规范
系统调用和用户空间中的函数调用存在一些不同点,以x86_64架构为例:
- 进程内核栈除了需要保存内核空间过程调用外,还需要保存用户空间栈的数据和返回地址,以便 在返回用户空间继续执行。
- 过程调用中寄存器调用约定不同。具体定义可查看源代码
1
2
3
4
5
6
7
8
9
10
11Registers on entry:
rax system call number
rcx return address
r11 saved rflags (note: r11 is callee-clobbered register in C ABI)
rdi arg0
rsi arg1
rdx arg2
r10 arg3 (needs to be moved to rcx to conform to C ABI)
r8 arg4
r9 arg5
(note: r12-r15, rbp, rbx are callee-preserved in C ABI)arch/x86/entry/common.c。
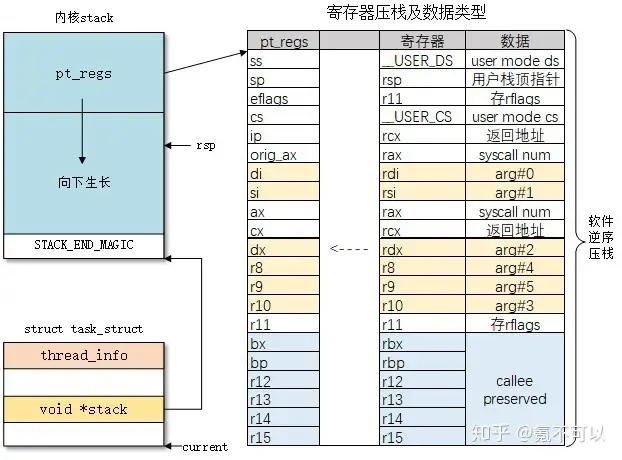
在代码 arch/x86/entry/entry_64.S 中可查看切换的具体过程:
- 用户栈到进程内核栈的切换(修改
rsp寄存器的值)。 - 依次将用户空间寄存器压栈,和数据结构
struct pt_regs成员一一对应(顺序固定且是倒序)。
内核的整体结构
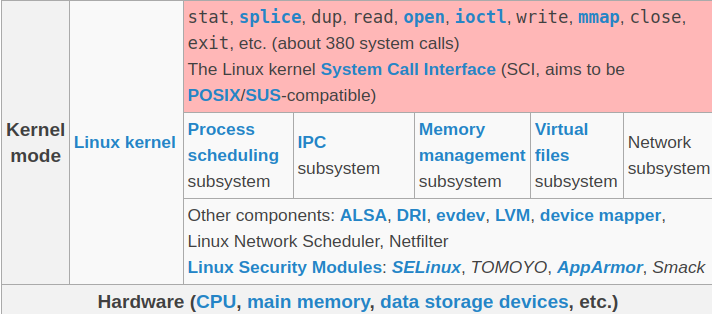
用一句话来总结内核的角色:内核是最懒的资源管理者。这里的资源可以分为三大类:CPU、内存和 I/O。内核通过抽象这些资源形成进程、线程、文件和虚拟内存等概念。抽象是对抗复杂性的很有效的手段之一。换句话说,内核也可以看作用户进程执行的环境。
内核的懒是它的特点也是对它的要求,特别是对于支持多任务并发的内核来说。除非被唤醒,它应该什么都不做;即使被唤醒,也应该做的尽量少、尽量快,然后继续”睡觉“。这种特性与整个系统并发的效率紧密相关。
进程/内核模式
将内核唤醒的方式几乎都是事件驱动的,这些事件简单来说分为中断和异常,中断又可以大致分为硬中断和软中断。POSIX定义了系统调用接口 API,系统调用也可以认为是软中断的一种,支持从用户程序唤醒内核,但标准并没有限制内核如何设计。
类Unix内核区分内核态和用户态。用户进程几乎不与硬件资源直接交互,而是使用系统调用进入内核态请求资源。
单内核(Monolithic kernel)与微内核(Microkernel)
可以用下面一张图来描述二者的不同:

很容易看出,微内核更简单、更模块化,但模块间的通信交互开销会更高。另外,微内核的 RAM利用效率会更高,因为不被调用的系统进程可以被换出。Linux 为了既吸收微内核的优势又不影响性能,提供了模块(Module)。模块是一个目标文件,可以在运行时链接到内核或者从内核解除链接。模块不是作为一个特殊的进程来执行,它代表当前进程在内核态下执行。
可重入内核
可重入内核也必须是可抢占内核。也就是说,即使当前 CPU 处于内核态,也仍然可以被抢占,这使得内核具有很高的实时性。可重入内核必须引入同步机制来访问共享数据结构。大多数传统的 Unix 内核都是非抢占内核,但 Linux 是可抢占内核,特别在 SMP 系统上,可抢占内核可以获得更好的并行性能。
同步机制可以包括禁止中断、信号量、自旋锁(针对SMP系统)。
子系统
进程管理
我们说内核是最懒的资源管理者,从内核的角度看,进程的目的就是担当分配系统资源(CPU时间、内存)的实体。
Linux 2.6 以后版本中的线程采用NPTL(Native POSIX Thread Library,本地POSIX 线程库)模型,操作速度得以极大提高,相比于Linux 2.4 内核时代的LinuxThreads模型,它也更加遵循POSIX规范的要求。
进程描述符
进程的核心数据结构是进程描述符(Process Descriptor, PCB),它的子段包含了与一个进程相关的所有信息。PCB 是相当复杂的,它不仅包含了很多进程属性的子段,而且包括了指向其他数据结构的指针。其大致结构如下(具体定义位于头文件include/linux/sched.h:624中,以 5.4 版本为例):
1 | struct task_struct{ |
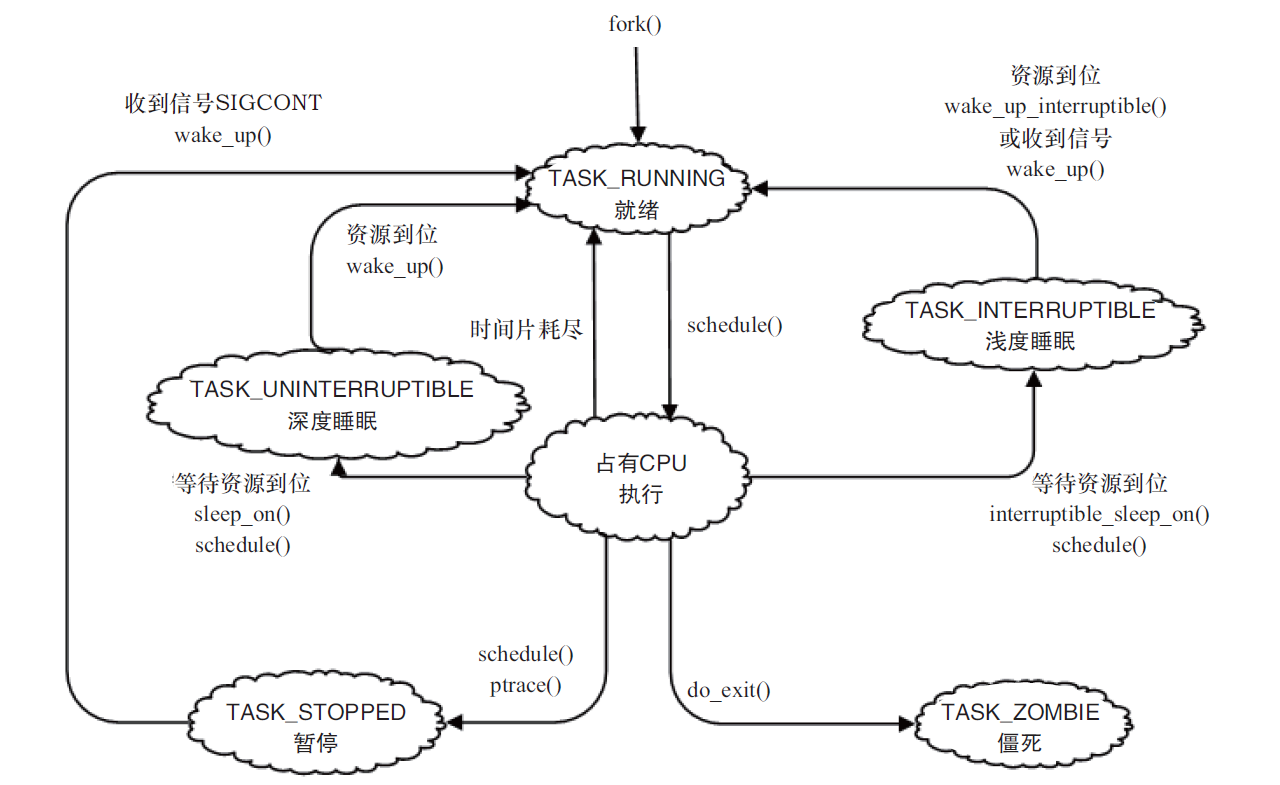
进程状态
状态转换图:
进程标识符
进程与进程描述符之间有严格的一一对应关系,可以使用进程描述符地址描述进程。另外,内核也允许用户使用 PID来标识进程,PID存放在 PCB 的 pid 字段中。另外tgid字段代表所在线程组中领头线程的 PID。 PID是 32 位的无符号整数,它被顺序编号。PID 是 内核提供给用户操作进程的接口。
内核必须有效地从进程 PID 导出它的进程描述符指针,效率非常重要。内核使用 pid 哈希链表pidhash来建立映射关系,内核引入了PIDTYPE_MAX 个 pid 哈希链表,在 PCB 中对应字段struct hlist_node pid_links[PIDTYPE_MAX]。
内核栈
在每一个进程的生命周期中,经常会通过系统调用(SYSCALL)陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先用户空间中的栈,而是一个内核空间的栈,这个称作进程的内核栈。每个 task 的栈都包含用户栈和内核栈两部分。进程内核栈的定义如下(include/linux/sched.h:1628):
1 | union thread_union { |
其中THREAD_SIZE 在 32 位系统是 8KB,64 位系统里是 16KB。那么,其中 thread_info 有什么用呢?
在不同的体系结构里,进程需要存储的信息不尽相同,Linux 使用task_struct存储通用的信息,将体系结构相关的部分存储在thread_info中。例如:
1 | /* x86 */ |
进程描述符 task_struct 中的字段void *stack指向内核栈。根据宏CONFIG_THREAD_INFO_IN_TASK 是否设置,我们可以分情况讨论。
首先,如果thread_info在进程内核栈中,我们可以得到下面的结构图(以 ARM 为例):
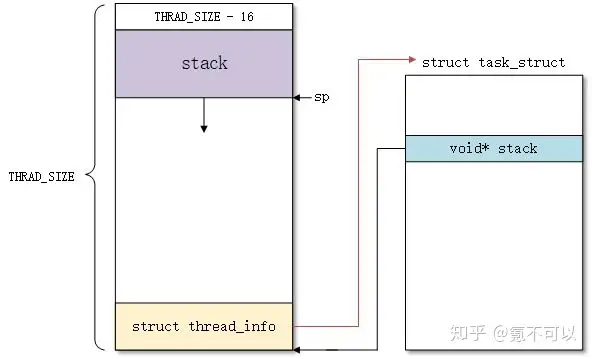
因此,我们可以获得当前进程内核栈的sp寄存器存储的地址时,根据THREAD_SIZE对齐就可以获取thread_info结构的基地址。
然后,如果 thread_info 结构在进程描述符中,以下面结构图所示: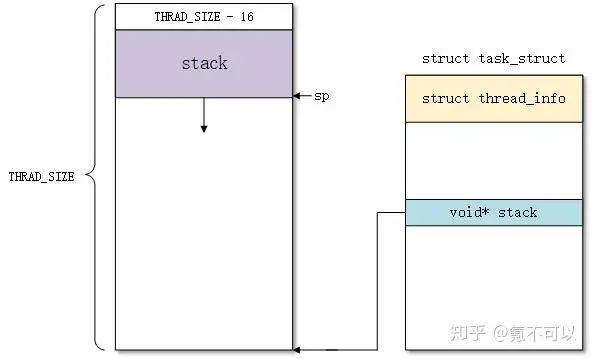
以上复杂的结构,用于实现current宏,来获得当前进程对应的 PCB 地址。例如对于 ARM 架构:
1 | // arch/arm/include/asm/thread_info.h |
ARM64 不再使用通过计算栈偏移量的方式获得进程 PCB 地址,而是使用寄存器sp_el0,在进程切换时暂存 PCB 地址。
而在 x86 体系结构中,linux 一直采用另一种方式:使用了current_task这个 CPU 变量,来存储当前正在使用的 CPU 的进程 PCB 地址。如下所示(arch/x86/include/asm/current.h):
1 | struct task_struct; |
其中DECLARE_PER_CPU 和 this_cpu_read_stable 用于支持 SMP 系统。
那么如何获得内核栈的栈指针呢?在x86架构中,使用特殊的段类型: TSS,它被用来存放硬件上下文。TSS 反映了 CPU 上的当前进程的特权级。linux 为每一个 cpu 提供一个 TSS段,并且在tr寄存器中保存该段。
在从用户态切换到内核态时,可以通过获取 TSS段中的 esp0来获取当前进程的内核栈 栈顶指针,从而可以保存用户态的cs,esp,eip等上下文。相关结构体和宏在arch/x86/include/asm/processor.h 中定义:
1 |
|
linux的tss段中只使用esp0和iomap等字段,并且不用它的其他字段来保存寄存器。在一个用户进程被中断进入内核态的时候,从tss中的硬件状态结构中取出esp0(即内核栈栈顶指针),然后切到esp0,其它的寄存器则保存在esp0指的内核栈上而不保存在tss中。
进程组织
所有(处于TASK_RUNNING状态的)进程被组织在双向链表中。在每个进程的 PCB 中都包含链表节点(struct list_head tasks),tasks和其他指针字段一起将所有进程组织成进程树。
表示进程间亲属关系的字段有parent、real_parent、children和sibling。进程之间还存在非亲属关系,例如一个进程可能是一个进程组或登陆会话的领头进程。这些字段包括group_leader、tgid等。
对于处于等待状态中的进程,内核将它放入被等待事件的等待队列中,并可以在未来条件满足时唤醒进程。等待队列由双向链表实现。
进程切换
进程切换任务主要由 siwtch_to宏完成,它定义在include/asm-generic/switch-to.h中:
1 | extern struct task_struct *__switch_to(struct task_struct *, |
同步机制
竞争和并发控制
SMP 架构
内核抢占
local_irq_enable 和 local_irq_disable 用于单核的本地中断的开关。对于 ARM 处理器而言,其实就是保存和恢复CPSR。
local_bh_enable 和 local_bh_disable 用于下半部(tasklet、sortirq)的开启和关闭。
原子操作
针对整型变量的原子操作
针对位的原子操作
锁机制
自旋锁、互斥体、信号量、读写锁和顺序锁。
自旋锁
自旋锁一般用于 SMP 和内核可抢占的情况。
自旋锁一般和 local_irq_xxxxx、local_bh_xxxxx 的使能和禁止结合使用,使得无论是在核 0 的中断上下文、进程上下文还是核 1 上的中断上下文、进程上下文都可以避免并发的可能性。
使用自旋锁需要注意:
- 自旋锁是忙等锁,因此,只有在占用锁的时间极短的情况下,使用自旋锁才是合理的。但临界区很大时或有共享设备的适合,需要较长时间占用锁,使用自旋锁会降低系统的性能。
- 自旋锁可能导致系统死锁。
- 自旋锁所保护的临界区不能睡眠或者其他引起进程调度的函数。
RCU
关于 RCU 的经典文档 Read-Copy Update。
不同于自旋锁, 使用RCU的读端没有锁、内存屏席、原子指令类的开销,几乎可以认为是直接读(只是简单地标明读开始和读结束),而RCU的写执行单元在访问它的共享资源前首先复制一个副本, 然后对副本进行修改, 最后使用一个回调机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据,这个时机就是所有引用该数据的CPU都退出对共享数据读操作的时候, 等待适当时机的这一时期称为宽限期(Grace Period)。
RCU可以看作读写锁的高性能版本,相比读写锁,RCU的优点存于既允许多个读执行单元同时访问被保护的数据。又允许多个读执行单元和多个写执行单元同时访问被保护的数据。但是,RCU不能替代读写锁,因为如果写比较多时,对读执行单元的性能不能弥补写执行单元同步导致的损失。因为使用RCU时,写执行单元之间的同步开销会比较大, 它需要延迟数据结构的释放、复制被修改的数据结构, 它也必须使用某种锁机剖来同步并发的其他写执行单元的修改操作。
内存屏障
完成量(Completion)
内存管理
架构
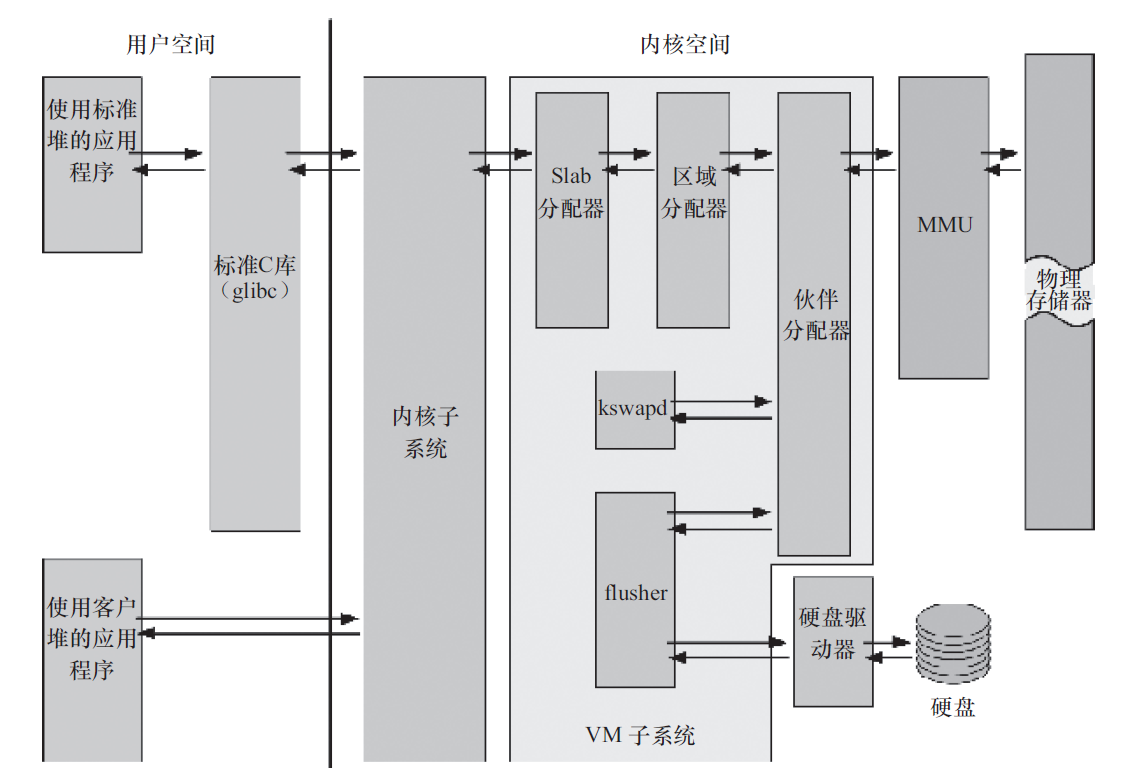
虚拟内存
从虚拟内存的角度来看,2.6 之后的内核融合了r-map(反向映射)技术,显著改善虚拟内存在一定大小负载下的性能。
分页
Linux 在32位系统使用传统的二级页表,在64位系统使用三级或四级页表。分页是内核与硬件共同协作完成的功能。概括来说,每个进程在自己的地址空间中都有属于自己的多级页表,并且在进程描述符中包含第一级页表的指针。该指针使用时会被写入一个特定的控制寄存器(在 80x86中为cr3控制寄存器)。在进程切换时,控制寄存器的值会被保存到前一个进程的进程描述符中,随后的地址翻译几乎全由硬件完成(MMU)。相关头文件:arch/<ARCH>/include/asm/{page.h, pgtable.h}等。
页表的每一项是一个无符号整数,其中包含标志位和(页或者下一级页表的)物理地址的高位。对于4k大小的页,页物理地址的低12位为0,所以正好可以放置标志位。重要的几个标志位如下:
| 位 | 名称 | 描述 |
|---|---|---|
| 0 | Present | 1: 该页在物理内存中;0: 该页没有分配,其他标志位无意义。 |
| 1 | Writeable | 1: 该页可写;0:该页只读。 |
| 2 | User/Supervisor | 1:用户可以访问该页;0:用户不可以访问该页。 |
| 3 | PWT | 1:该页对应的 cache 使用write through模式;0:使用write back模式。 |
| 4 | PCD | 1:该页不能被cache;0:是否可以被cache,由cr0寄存器的CD位决定。 |
| 5 | Access | 该页被访问(读/写)后,被置1;用户可以置0;此位决定了该页的地址映射关系是否可以被 TLB缓存。 |
| 6 | Dirty | 该位只对映射非线性磁盘文件的页有意义。当该页被写入时,则置1;后续需要回收页时,该页被flush到下级存储,然后此位被置0。 |
| 7 | PSE/PAT | 1:PSE,使用4M或2M的页;0:PAT,使用4k的页。 |
| 8 | Global | 该位用于决定在上下文切换时是否需要冲刷(flush) TLB 中的 entry。 |
内核页表
高速缓冲和TLB
高速缓存处于内存和寄存器之间,一般使用 SRAM 实现。高速缓存与内存的一致性由 CPU 自动同步;但 TLB 与进程页表的同步需要内核来完成。
文件系统
VFS
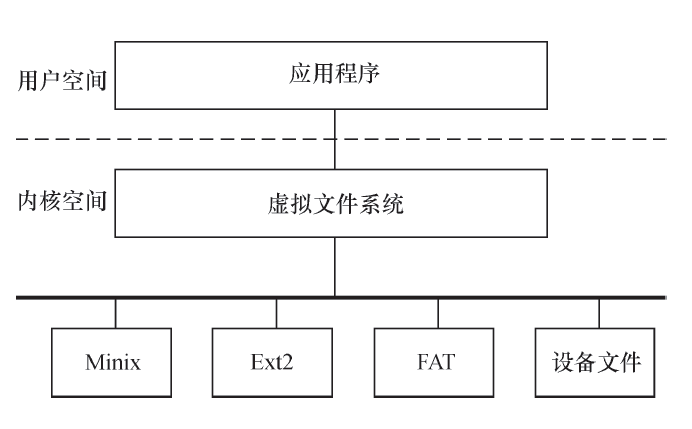
网络
体系结构
设备驱动
内核一般要做到drivers与arch的软件架构分离,驱动中不包含板级信息,让驱动跨平台。同时内核的通用部分(如kernel、fs、ipc、net 等)则与具体的硬件(arch 和drivers)剥离。
udev
udev 取代 devfs(关于策略与机制的分离,内核负责提供机制,和策略相关的事情放到用户空间来做)。
udev 完全在用户态工作, 利用设备加入或移除时内核所发送的热插拔事件(HotplugEvent)来工作,在热插拔时,设备的详细信息会由内核通过netlink套按字发送出来, 发出的事件叫uevent。udev的设备命名策略、权限控制和事件处理都是用户态下完成的, 它利用从内核收到的信息来进行创建设备文件节点等工作。
设备模型
Linux 2.6以后的内核引入了sysfs文件系统,sysfs被看成是与proc 、devfs和devpty同类别的文件系统。
sysfs把连接在系统上的设备和总线组织成为一个分级的文件。它们可以由用户空间存取,向用户空问导出内核数据结构以及它们的属性。 sysfs的一个目的就是展示设备驱动模型中各组件的层次关系。
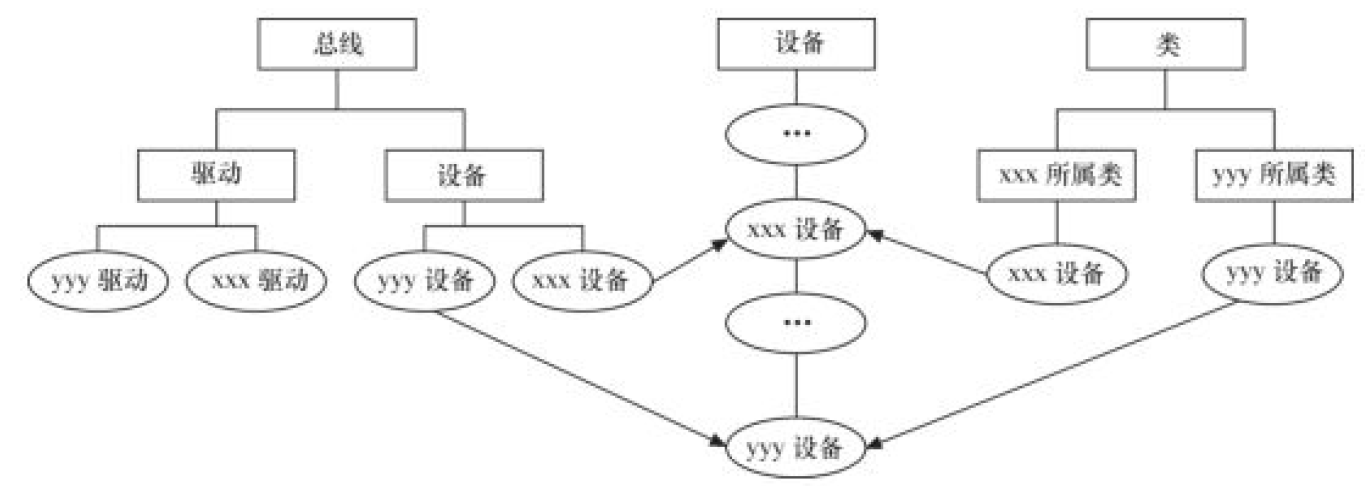
从代码分析的角度看,struct bus_type 定义总线,struct device_driver 定义驱动,struct device 定义设备,struct class 定义类。驱动和设备是分开注册的,依靠 bus_type 的 match() 函数将两者绑定到一起,一旦配对成功,xxxx_driver 的 probe() 函数就被执行(xxxx 是总线名,如platform、pci、i2c、spi、usb等)。
总线、驱动和设备最终都会落实为
sysfs中的 1 个目录,因为进一步追踪代码会发现,它们实际上都可以认为是kobject的派生类,kobject可看作是所有总线、设备和驱动的抽象基类,1 个kobject对应sysfs中的 1 个目录。总线、设备和驱动的各个attibute则直接落实为sysfs中的一个文件,attribute会伴随着show()和store()这两个函数。
字符设备
struct cdev 结构体描述了一个字符设备。
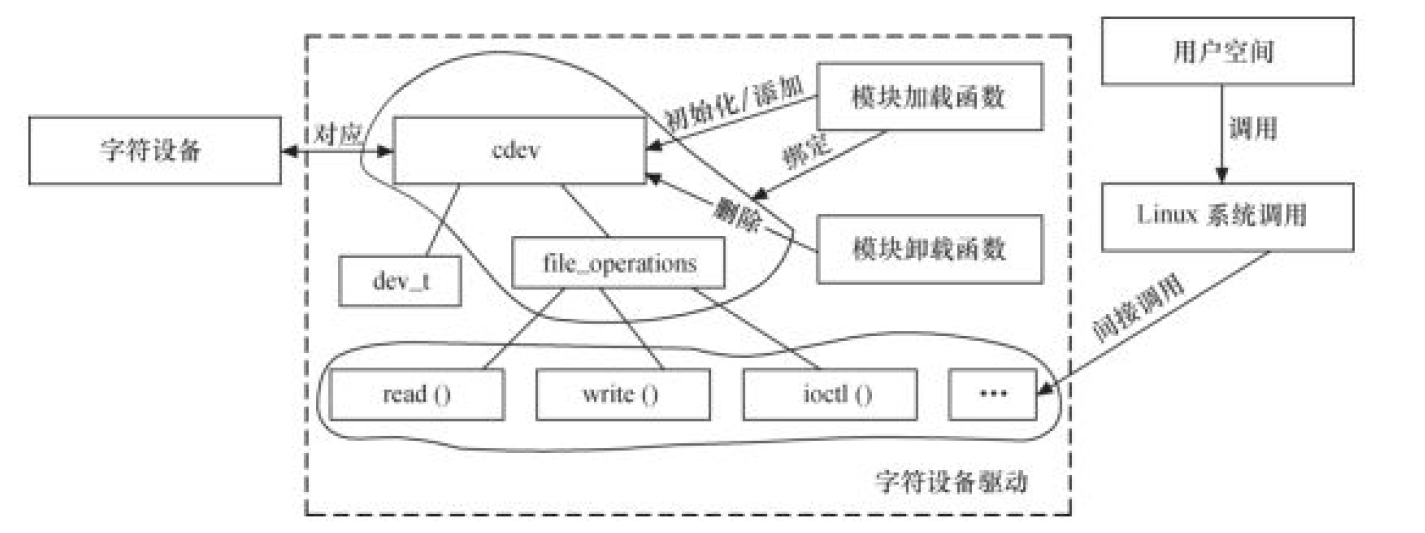
a. 加载和卸载函数
在加载函数中应该实现设备号的申请和 cdev 的注册,而在卸载函数中应该实现设备号的释放和 cdev 的注销。
b. file_operations 结构体中的成员函数
file_operations 结构体中的成员函数是字符设备驱动与内核虚拟文件的接口。
特别注意的是,在这些接口中,很多需要进行内核空间与用户空间的数据拷贝,内核必须检查用户空间缓冲区的合法性显得尤其重要,很多内核漏洞都是因为忽略这一检查造成的。攻击者可以伪造一片内核空间的缓冲区地址传入系统调用的接口,让内核对这个 evil 指针指向的内核空间填充数据。
内核在实现 copy_from_user() 和 copy_to_user() 等函数时会调用 access_ok() 函数,该函数会做用户空间地址合法性检查。
Linux 驱动的软件架构
Linux 设备驱动非常重视软件的可重用和跨平台能力,驱动和硬件平台信息应该解耦。Linux 设备、驱动和总线结合起来可以做到这一点。另外 Linux 也采用分层机制,将驱动层中通用的部分提炼为一个中间层,减少驱动层的复杂性。
设备和驱动的分离: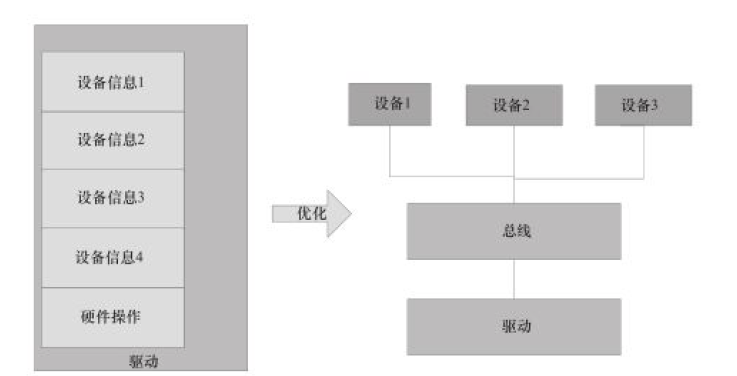
Linux 驱动的分层: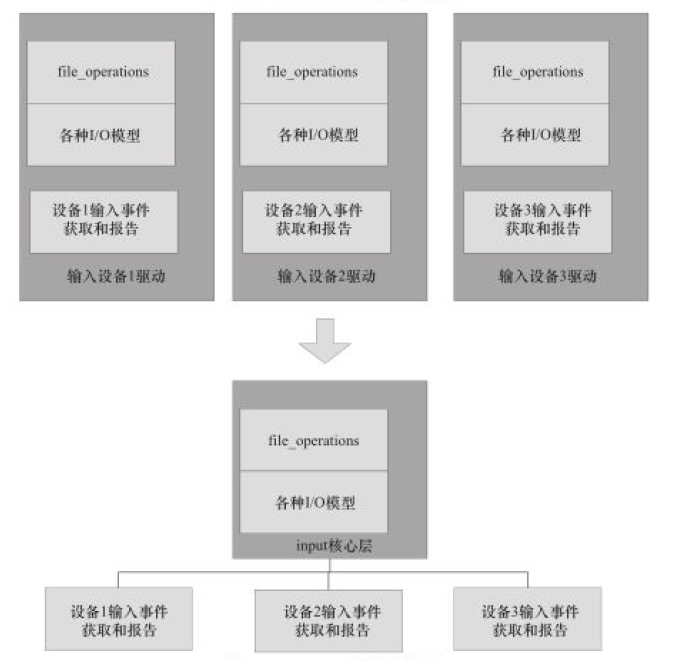
分隔: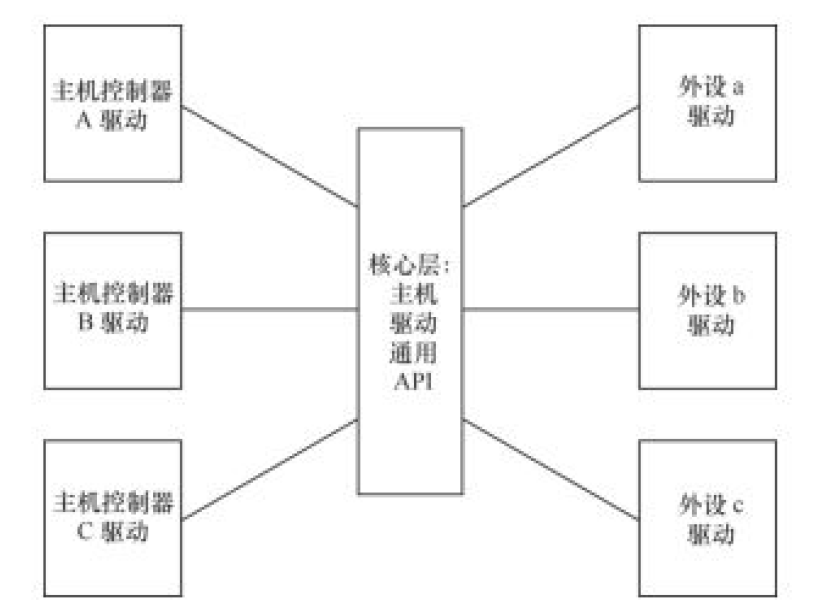
Linux 为 SoC 内存空间的外设(SoC中集成的独立外设控制器)发明了一种虚拟的总线,称为 platform 总线,相应的设备称为 platform_device,而驱动称为 platform_driver(与 i2c_driver、spi_driver、usb_driver、pci_driver 对等)。
如前文所述,系统也为 platform 总线定义了 bus_type 的实例 platform_bus_type ,如下所示:
1 | struct bus_type platform_bus_type = { |
其中 match() 函数用于确定 platform_device 和 platform_driver 的匹配。
四种匹配方法:
- 基于设备树风格的匹配
- 基于
ACPI风格的匹配 - 匹配
ID表(即platform_device设备名是否出现在platform driver的ID表中) - 匹配
platform_device设备名和驱动的名字。
在设备驱动中引入 platform 的概念至少有如下好处:
- 使设备被挂载在一个总线上,符合 Linux 2.6 以后内核的设备模型。
- 隔离
BSP和驱动。在BSP中定义platform设备和设备所使用的资源、设备的具体配置信息,而在驱动中,只需要通过调用API去获取资源和数据。使得驱动具有更好的可扩展性和跨平台性。 - 让一个驱动支持多个设备实例。
这中分层设计类似于面向对象的编程模型。
Linux 内核输入子系统
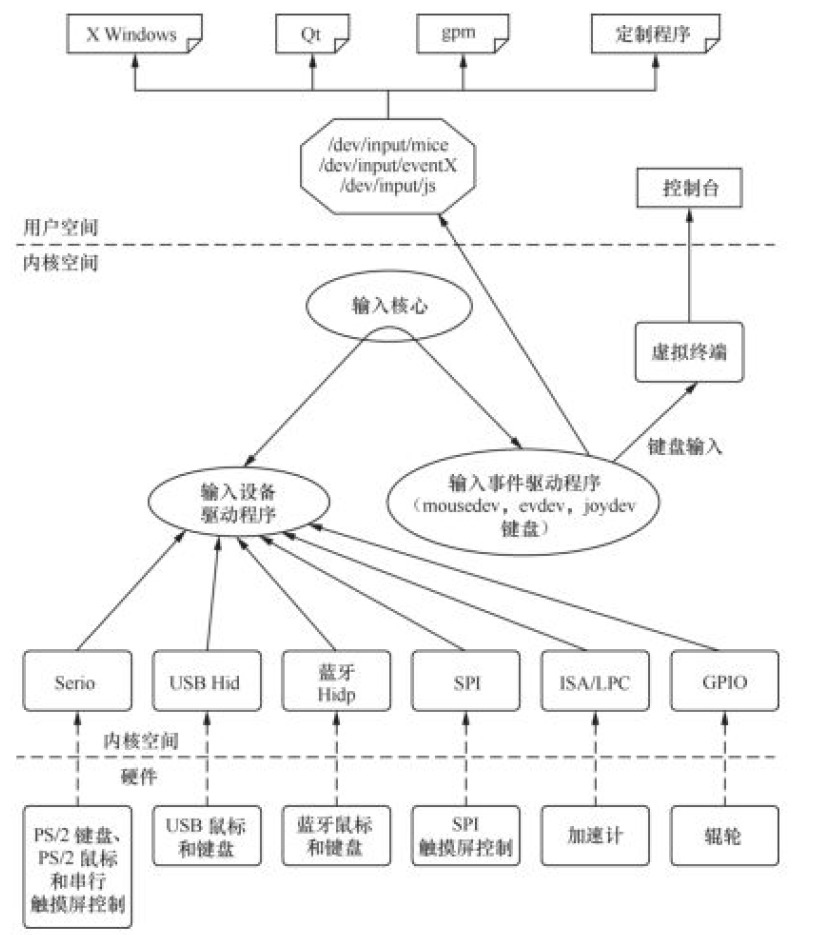
驱动的核心层的职责:
- 对上提供接口。file_operations 的接口被中间层完成,各种 IO 模型也被处理。
- 中间层实现通用逻辑。
- 对下定义框架。底层的驱动不需要关心 Linux 内核
VFS的接口和各种可能的 IO 模型,而只需要处理和硬件相关的访问。
主机驱动和外设驱动分离的核心思想。