MPI Tutorial
概述
在并行 MIMD(多指令多数据)的世界中的大多数计算机都可以分为分布式内存型和共享内存型两种类型的系统。我们在OpenMP Tutorial 中介绍了后一种,从编程人员的角度看,共享内存型的系统由多个核及可以全局访问的内存组成,在那里任何核可以访问任何内存地址。我们这篇文章介绍前一种系统的并行编程,通过使用一种消息传递(Message-Passing)接口 API。
参考 《Introduction to ParallelProgramming》 by Peter Pacheco.
熟悉 Linux/Unix 系统编程的开发人员会自觉地将 MPI 接口与部分进程间通信机制进行类比。常用的非共享内存的进程间通信机制包括管道、信号、消息队列等,但这些机制并不适合跨系统的分布式系统编程。
下载安装 MPI 实现
MPI 作为一种标准,可以有多种实现。
MPICH 是一种高性能和可移植的 MPI 的实现,它的目标如下:
- 有效支持不同类型的计算和通信平台,包括商用集群(commodity clusters)、高速网络和高端计算机系统(例如Blue Gene 和 Cray)。
- 通过一种已扩展的模块化的框架来支持使用 MPI 的尖端研究。
在 Ubuntu 系统上下载:sudo apt-get install mpich
我们可以看到该包依赖另外两个包libmpich-dev 和 libmpich12,它分别代表头文件和动态链接库(支持c/c++/fortran语言)。
OpenMPI 是 MPI 标准的另外一种实现。
在 ubuntu 上下载安装: sudo apt-get instal libopenmpi-dev libopenmpi3 openmpi-bin opemmpi-common。这些包包含了头文件、动态链接库和相关工具等。
我们下面的示例将使用 openmpi 实现。
一个 HelloWord 程序
我们把消息传递的主体称作进程(基本上与实际的进程等价),进程间的通信通过两个函数完成:send 函数和receive函数。
1 |
|
在上面的程序中,进程0接收来自其他非0进程的消息(通过一个for循环),非0进程则向进程0发送消息,编译该程序:
$ mpicc -g -Wall -o hello_mpi hello_mpi.c
mpicc 是对 C 编译器的包装器,它简化了编译命令,使得用户不需要考虑指定头文件路径或链接动态库等编译选项。当然,我们也可以支持使用 C 编译器:
$ gcc -g -Wall -o hello_mpi hello_mpi.c -lmpi
我们可以直接运行 ./hello_mpi:
1 | ./hello_mpi |
可以看到只有一个进程 0 被生成,并没有进程间通信。我们使用 mpiexec 来生成多个实例进程:
1 | mpiexec -n 2 ./hello_mpi |
mpiexec -n <number> ./hello_mpi 命令首先会让系统生成 number 个 ./hello_mpi 程序实例(进程),然后可能会让系统调度不同的实例到不同的 Core 上运行,一旦所有进程运行后,MPI 实现会负责确保进程间可以相互通信。在我的系统上只有两个 Core,所以 number 最大为 2 。
也可以使用 硬件线程 来完成并发执行:
$ mpiexec -n 3 --use-hwthread-cpus ./hello_mpi
主要 API
MPI_Init 和 MPI_Finalize
MPI_Init 接口的原型如下:
int MPI_Init (int* argc_p, char*** argv_p);
argc_p 和 argv_p 分别指向 main函数的 argc和 argv,MPI_Init 可以接管对命令行参数的处理,如果不需要,则将 argc_p 和 argv_p 置为 NULL。MPI_Init 接口负责 MPI 系统的初始化,例如为消息Buffer分配存储空间,为进程实例分配 Rank 等。也就是说,MPI_Init 必须在所有其他 MPI_XXXX 接口前调用。
MPI_Finalize 接口的原型如下:
int MPI_FInalize(void);
MPI_Finalize 会通知 MPI 系统我们已经完成了 MPI, 它会释放内部的动态内存空间。
###3.2 MPI_Comm_size 和 MPI_Comm_rank
MPI 系统定义了 通讯者(Communicators)的概念,它代表所有彼此可以通信的进程。在具体接口定义中,称为 MPI_COMM_WORLD。
MPI_Comm_size 接口的原型如下:
int MPI_Comm_size(MPI_Comm comm, int* comm_sz_p);
该接口返回 Communicators(即形参 comm) 中所有进程的个数。
MPI_Comm_rank接口的原型如下:
int MPI_Comm_rank(MPI_Comm comm, int* my_rank_p);
该接口返回Communicators(即形参 comm) 中当前进程(即当前调用 MPI_Comm_rank的进程)的排名(Rank)。
SPMD 程序
在我们上面的 HelloWorld 例子中,所有的进程都共用同一个程序,但在程序内部使用if-else分支语句区分非0进程和0号进程的行为,进程的排名(Rank)通过调用 MPI_Comm_rank接口获得。这种并行编程的方法可以称为 SPMD(单程序,多数据)。SPMD 程序可以被任意多个进程运行。
MPI_Send
MPI_Send 接口的原型为:
1 | int MPI_Send(void* msg_buf_p, int msg_size, MPI_Datatype msg_type, |
msg_buf_p 指向消息的内容,msg_size 和 msg_type 共同决定了消息的大小。MPI_Datatype 代表数据单元的类型,类型列表如下:
- MPI_CHAR,MPI_UNSIGNED_CHAR
- MPI_SHORT,MPI_UNSIGNED_SHORT
- MPI_INT,MPI_UNSIGNED
- MPI_LONG,MPI_UNSIGNED_LONG
- MPI_LONGLONG
- MPI_FLOAT
- MPI_DOUBLE,MPI_LONG_DOUBLE
- MPI_BYTE
- MPI_PACKED
dest 代表目标进程的Rank,tag是非负整数,用来区分不同的消息(这是一种语义上的不同),communicator 代表通讯者,所有通讯类 MPI 接口都必须包含该参数。Communicators 定义了一种”通信宇宙”,不同Communicators中的进程不能相互通信。
例如,在某些场景中,我们需要使用两个库,它们都使用了MPI,但它们是独立建模的。我们需要防止两个库中的进程相互通信,一种简单的做法就是为两个库使用不同的Communicators。
需要特别注意的是,MPI_Send 接口的调用可能会使当前进程阻塞,也可能立即返回。MPI 为不同的语义提供了不同的接口。在MPI_Send的语义层面,对于消息的发送而言,不同实现有不同的细节。通常来说,我们使用 “信封” 模型,信息是 “信”,但我们需要增加一些额外的信息放在“信封”上面,这些信息包括:目标进程Rank、当前进程Rank、消息Tag、Communicators和消息的长度等。
MPI_Recv
MPI_Recv 接口的原型为:
1 | int MPI_Recv(void* msg_buf_p, int msg_size, MPI_Datatype msg_type, |
大部分参数与 MPI_Send 接口相同,其中 source 代表消息来源进程的Rank;tag则需要和发送者 MPI_Send 中的 tag 保持匹配,communicator 也需要和发送者进程所在的Communicators保持匹配;status_p 大部分情况不会被用到,我们传递 MPI_STATUS_IGNORE 实参给它。
特别注意的是,MPI_Recv总是会阻塞,直到一个匹配的消息被完全接收。MPI 也提供了非阻塞的通信接口。
MPI 要求消息是 非重叠的(nonovertaking),即如果一个进程 q 发送了两个消息给进程 r,那么在接收第二个消息之前,第一个消息对于r来说必须是可用的。但对于不同进程发送的消息,就没有这样的限制。换句话说,进程 m 相对进程 n 更早地向进程 r 发送消息,但并不代表进程 r 会更早地接收它。MPI 可能会运行在地理布局非常大的分布式系统中,这种系统中节点之间的网络通信速率可能相差很大。
消息匹配
发送信息的进程 q 如果要确保信息被目标进程 r 接收,需满足以下条件:
- tag 要一致
- communicator 要一致
- dest = r 并且 source = q
- msg_type 要一致,而且 r 的 msg_size 要大于等于 q 的 msg_size。
这里有一个特殊情况,如果进程 r 从多个进程接收消息,这些进程完成任务的时间是不可预测的;如果 r 简单的以进程的排名顺序来接收消息,可能会导致部分“快进程”需要等待“慢进程”完成。为避免这个问题,MPI 提供了 MPI_ANY_SOURCE 常量,它可以作为进程 r MPI_Recv 接口中 source 的实参。这样进程 r 就可以按照发送者进程的完成顺序来接收消息。
类似的做法适用于 tag 形参。MPI 提供了 MPI_ANY_TAG 常量,它可以作为 MPI_Recv 中 tag 的实参,这使得 r 进程不用再指定不同tag消息的接收顺序。
MPI_ANY_TAG 和 MPI_ANY_SOURCE 统称为 “通配符(Wildcard)” 参数,它的使用需要注意:
- 只能有一个接收进程使用 “通配符” 参数。
- 对于
Communicator参数没有”通配符” 实参。
在实际编程中,消息匹配是非常重要的,如果使用 MPI_Recv 的进程没有接收到匹配的消息,它会一直阻塞。对于使用 MPI_Send 的进程,如果发送的信息没有任何接收进程匹配,那么它也会阻塞(如果使用非阻塞接口,发送的信息会丢失)。
status_p 参数
在 3.6 节中我们说明了”通配符” 参数的使用,那么接收进程如何获取消息的发送者、消息的tag和消息的实际大小呢?
使用 MPI_Recv 接口的 status_p 参数可以用来获取这些信息,它是一个至少包含下面三个成员的结构体:
- MPI_SOURCE : 指定消息的发送者
- MPI_TAG: 指定消息的tag
- MPI_ERROR
消息的大小可以使用 MPI_Get_count 接口获取,其原型为:
int MPI_Get_Count(MPI_Status* status_p, MPI_Datatype type, int* count_p);
其中 status_P 和 type 要使用与MPI_Recv接口中相同的实参。
一个复杂例子
数值积分
与OpenMP Tutorial 中相同,我们仍然以“使用梯形法则进行数值积分“作为例子:
1 |
|
从上面的代码中可以看出,被积分函数为f(x) = x*x ,进程 0 除了完成自己的计算任务外,还负责接收其他进程的计算结果,并累加到最后的积分结果中。
编译后运行结果如下:
1 | mpiexec -n 2 ./tap |
关于I/O
对于同一 Communicator中的进程,输出端口stdout是共享的。如果多个进程同时使用它,就会产生竞争行为,输出结果的顺序也是无法预测的。 对于 stdin 输入端口,大多数 MPI 的实现只允许进程 0 访问 stdin,然后再由进程 0 将输入数据发送给其他进程。
聚合通信
4.1 节中的例子存在什么问题呢?我们可以看到进程0有点“委屈地”完成所有的求和处理,而其他进程仅仅告诉进程0 ”将我的结果加到最终结果上“ 后就退出了。为了进一步提高通信效率,我们将尝试使用一些其他的通信布局。
树形通信
我们可以用下图来描述树形通信的一种类型,在这里求和工作可以在多个进程中并行执行,而不是像4.1中那样只有进程0来完成。
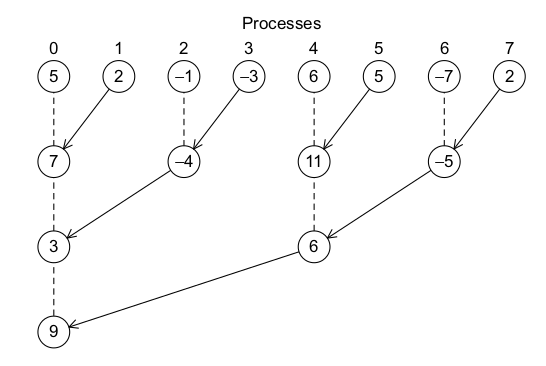
树形通信虽然有很大的优势,但编程更加复杂。而且在不同的场景下,使用哪一种树形结构并不是预先知道的。
幸运的是,MPI实现 提供了方便的接口来帮助用户获得优化的 “全局求和函数(global-sum function)” 。与MPI_Send和MPI_Recv只代表两个进程的通信不同,“全局求和函数”包括了所有进程,我们也称这种通信为 聚合通信(collective communications)。为了区分,MPI_Send和MPI_Recv 经常被称为点对点通信。
MPI_Reduce
实际上,全局求和只是整个聚合通信大类中的特例。例如,全局求积、全局求最大值/最小值等也是聚合通信的例子。
MPI 泛化了全局求和函数,使得它可以使用一个函数来实现多种类型的聚合通信,这个函数就是MPI_Reduce:
1 | int MPI_Reduce (void* input_data_p, void* output_data_p, int count |
MPI_Reduce函数的通用性体现在 MPI_Op 参数中,它代表操作符(就4.1节中的例子而言,该参数的实参应该是MPI_SUM),MPI 提供了多种类型的操作符。(对于熟悉函数式编程的用户来说,MPI_Reduce类似于高阶函数,它定义了聚合的概念,但并不依赖具体聚合类型。)
4.1 节中的全局求和代码if(my_rank==0){...}else{...} 可以替换为下面一条语句:
1 | MPI_Reduce(&local_int, &total_int, 1, |
值的注意的是,count参数可以使得 MPI_Reduce 可以操作数组而不仅仅操作标量数据。
MPI 预定义的 Reduction 操作符如下:
- MPI_MAX, MPI_MIN
- MPI_SUM, MPI_PROD
- MPI_LAND,MPI_BAND
- MPI_LOR, MPI_BOR
- MPI_LXOR,MPI_BXOR
- MPI_MAXLOC,MPI_MINLOC
用户也可以定义自己的操作符。
对于聚合通信和点对点通信的区别,还需要特别注意以下几点:
- 在
Communicator中的所有进程必须调用相同的聚合函数。 - 每个进程调用 MPI 聚合函数的实参必须 “兼容”。
output_data_p参数只会在dest_process进程中用到。但其他进程仍然需要传递对应的实参,即使它的值为 NULL。点对点通信的匹配基于Communicator和 tag,但聚合通信的匹配不基于 tag ,它基于Communicator和聚合函数被调用的顺序。
MPI_Allreduce
在前面的例子中,只有进程0可以获得最终求和结果并打印出来,但有时候其他进程也需要获得全局求和结果来完成一些更大的计算。为了做到这点,我们可以在进程0获得结果后再分发给其他进程,以下面的反转树为例:
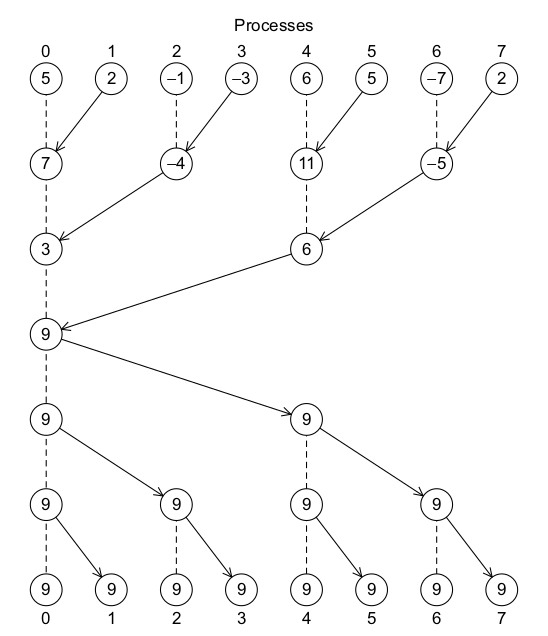
另外,我们也可以使用一种称为 Butterfly 的通信模型:
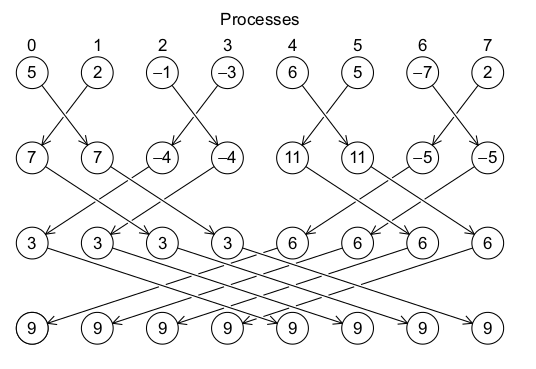
类似的,MPI 为用户提供了接口 MPI_Allreduce,该接口负责具体使用哪种分发模型获得最好的通信效率。MPI_Allreduce接口的原型如下:
1 | int MPI_Allreduce (void* input_data_p, void* output_data_p, int count |
和MPI_Reduce不同的是,这里没有 dest_precoss 参数,因为所有的进程都应该获得最终结果。
广播 MPI_Bcast
在4.2中,我们描述了 MPI 对输入输出的处理,在那里我们说进程0会将输入数据发送到其他进程。 一种简单的方法仍然是使用MPI_Send和MPI_Recv,进程0会在以一个for循环中向每个进程 MPI_Send 输入数据。我们可以想到使用树形结构进行优化(就像聚合函数一样),在聚合通信中,一个进程向所有其他进程发送数据称为一次广播(Broadcast)。MPI 提供了 广播函数:
1 | int MPI_Bcast(void* data_p, int count, MPI_Datatype datatype, |
进程source_proc将由data_p指向的数据内容发送给所有comm 中的进程(包括它自己吗?)。
例如4.1节中的 a, b, n 可以在进程0中通过stdin输入,然后再广播给其他进程,如下所示:
1 | void Get_input(int my_rank, int comm_sz, double *a_p, |
MPI_Scatter
在上节中我们说单个进程可以使用 MPI_Bcast 向其他所有进程广播数据,最后所有的进程得到的数据是相同的。但有时候我们不愿意这样做,例如在“求向量A和向量B的和”的程序中,A与B在进程0中输入,但进程0不需要将所有A和B的所有项广播出去,它只需要传播其他进程所需要的项即可。MPI_Scatter可以满足这样的需求,其原型为:
1 | int MPI_Scatter(void* send_buf_p, int send_count, |
send_buf_p 所指向的数据(假设共有 n 项)将会被 MPI 分成 comm_sz 份,例如如果使用块划分(与OpenMP中的块划分类似),那么进程0将获得前n/comm_sz项,进程1获得接下来的 n/comm_sz项,依次类推。每个进程需要传递本地向量指针作为recv_buf_p的实参,recv_cnt必须等于n/comm_sz。send_type与recv_type必须匹配,src_proc需等于 0 。注意send_count也要等于n/comm_sz。
MPI_Gather
MPI_Gatter 接口负责将所有的分组数据收集起来:
1 | int MPI_Gather(void* send_buf_p, int send_count, |
它与MPI_Scatter几乎相同,dest_proc需等于 0 。
MPI_Allgather
我们以矩阵-向量乘法程序为例,y = Ax,其中 x 为 n 维向量,A为 m 行 n 列的矩阵,那么 y 为 m 维向量。一个串行的程序如下:
1 | void Mat_vect_mult(double A[], double x[], double y[], int m, int n) { |
这里使用一维数据模拟矩阵 A 。我们如何并行化这个程序呢?
我们以 A 的行来划分任务,即前m/comm_sz行分配给进程0,接下来的m/comm_sz行分配给进程1,依次类推。等价于,向量 y 的前m/comm_sz项的求取分配给进程0,接下来的m/comm_sz项的求取分配给进程1,依次类推。
向量 x 与 向量 y 如果在聚合通信中使用相同的数据分发机制(如MPI_Scatter),那么我们就需要对 x 作额外的处理。因为在每个进程中我们需要知道 x 的所有项,我们想到可以使用 MPI_Bcast + MPI_Gather来满足该需求,但可以使用性能更好的 MPI_Allgather接口(它使用 Butterfly广播模型)。
该接口的原型如下:
1 | int MPI_AllGather(void* send_buf_p, int send_count, |
与MPI_Gather相比,我们不再需要dest_proc参数,因为我们收集的数据来自于所有进程而不是进程0(这也是Butterfly广播模型拥有更高通信效率的原因);而且所有的进程都获得了收集后的数据,而不仅仅是MPI_Gather中的dest_proc进程。
现在我们可以编写并行版本的矩阵-向量乘法程序:
1 | void Mat_vect_mult(double local_A[], double local_x[], |
MPI 派生数据类型
在分布式环境中,通信的代价往往比本地计算要昂贵,因此每次通信应该发送/接收尽量多的数据(还一种说法就是,我们应该减少发送 Message 的个数)。MPI 提供了三种方法来合并(consolidating)数据:
- 通信函数中的
count参数 - 派生数据类型(derived datatype)
MPI_Pack/MPI_Unpack接口
MPI 派生数据类型类似于 C 语言的结构体,例如我们5.4节中Get_Input()中的三个广播函数可以优化为一个,只要我们定义一个派生数据类型{(MPI_DOUBLE,0), (MPI_DOUBLE, 16),(MPI_INT,24)}。(类型+偏移量)
MPI_Type_create_struct接口用来定义派生数据结构,其原型为:
1 | int MPI_Type_create_struct(int count, int array_of_blocklengths[], |
对于我们的例子:
1 | int count = 3; |
为了获得 array_of_displacements 中数据成员的偏移量,可以使用 MPI_Get_address接口:
1 | int MPI_Get_address(void *location_p, MPI_Aint* address_p); |
其他可参考文章
- 《MPI,OpenMPI 与深度学习》
- 《MPI Tutorial Introduction》 By Wes Kendall.