LLVM 2: Backend
概述
在 LLVM 项目介绍 中我们说 LLVM 的后端代码生成器是由 一系列 Pass 组成的,本篇文章会进一步描述一些重要的 Pass:例如指令选择及其所使用的目标描述语言(.td文件)的细节。如果需要一个新的后端,在大多数情况下,我们都可以通过移植已经存在的后端来完成。
参考 Writing an LLVM Backend
参考 Creating an LLVM Backend for the Cpu0 Architecture。
参考 The LLVM Target-Independent Code Generator。
参考 The Architecture of Open Source Applications by Chris Lattern.
参考 《Learn-LLVM-12》 by Kai Nacke.
主要流程
后端的工作流程大致如下图所示:
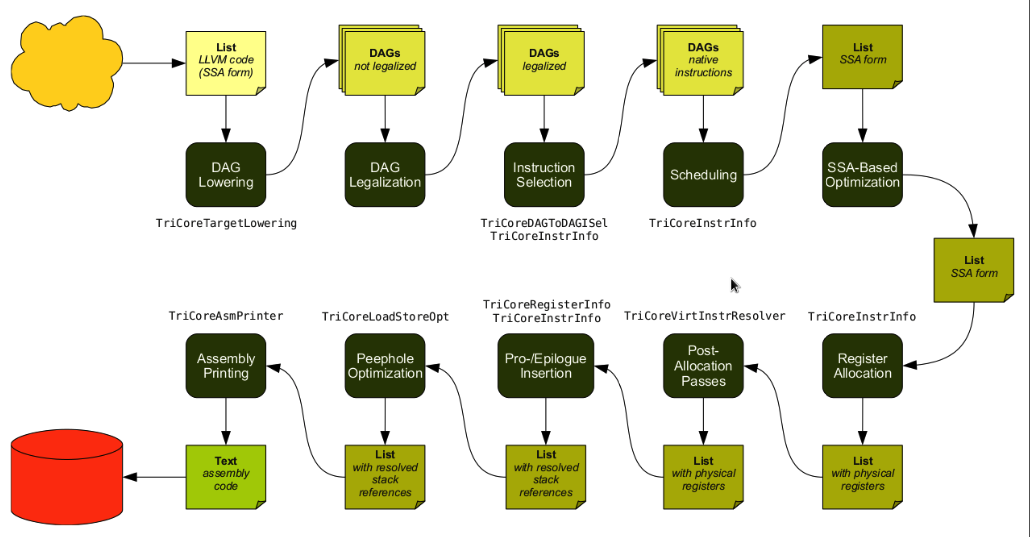
后端的主要工作任务总结如下:
- 指令选择
- 基于 SSA 的机器代码优化
- 寄存器分配
- Prolog/Epilog 代码插入
- 后期机器代码优化
- 代码 Emission
所有这些步骤都是由 MachineFucntionPass类派生的子类实现的,它自己是 FunctionPass的子类。在整个过程中,LLVM 指令会进行一系列的转换,首先对于输入 IR 中的每个指令在代码层对应 Instruction 类的实例;在 指令选择Pass 完成后,它转换为 MachineInstr类的实例,它更接近于实际机器表示,但仍使用虚拟寄存器;后面的 Pass 会对其继续进行转换,直到最后生成 MCInstr类的实例,它是真实机器指令的表示。
我们以下面的 LLVM IR code 作为例子(sum.ll):
1 | define i16 @sum(i16 %a, i16 %b) { |
使用 llc 编译,并输出中间 Pass 列表:
$ llc -mtripe=mips-linux-gnu -debug-pass=Structure < sum.ll
后端的 Pass 大多数不是在 LLVM IR 上运行,而是在 MIR 上运行,它是依赖于目标指令的表示。但它仍可以包含虚拟寄存器,所以并不是纯粹的 目标CPU 指令。我们可以在每个 Pass 完成后停止,并打印 MIR 的文本表示,如下所示:
$ llc -mtripe=mips-linux-gnu -stop-after=finalize-isel < sum.ll
它指示 llc 在 指令选择 Pass 后转储 MIR ,部分内容如下:
1 | name: sum |
MIR 中的细节可以参考文档 MIR 语言参考。
指令选择
指令选择可以使用树重写(Tree Coverage)方法或者 DAG方法来完成。其中,DAG 表示方法可以生成更好的代码,但匹配更加复杂。即使如此,LLVM 使用 SelectionDAG 作为基础的指令选择器(Instruction Selector)。该指令选择器的一部分是由 .td文件生成的,虽然 LLVM 正致力于在未来完全使用.td文件来生成指令选择器,但目前仍需要直接使用部分特定的 C++ 代码。GlobalISel 致力于替换SelectionDAG和FastISel,提供更高性能、更加模块化的指令选择器。
树重写方法首先需要为当前目标 ISA 中的指令构建 模板树,其中树的叶子可以是寄存器、常量或者内存地址(可能会带有附加的语义约束信息)。接下来需要进行树模式匹配,例如如果 IR 以 输入树 的形式表示,我们将 输入树 中的子树与树模板匹配,一旦成功,就输出对应的指令并替换 输入树 中的对应节点。重复该匹配过程,直到输入树归约为单个节点。另外,作为核心的树模式匹配的具体实现是如何呢?一种方法是:可以将输入树转换为基于前缀的文本串,模板树转换为上下文无关文法的产生式,那么接下来只需要使用 LR 语法分析技术就可以完成模式匹配了。
SelectionDAG是一种代码表示的抽象方法,它不仅适合以自动化技术进行指令选择,而且适合其他子流程,例如基本块的底层优化(常量折叠、公共子表达式消除、死代码消除等)。SelectionDAG 由 SDNode 类型的节点组成,该节点表示的操作称为 OpCode,除了操作外,该节点还存储操作数及其生成的值。节点的值和操作数形成数据依赖关系,另外使用“链边”表示控制流依赖关系,这使得保留具有副作用的指令的顺序称为可能,例如:load、store、call和return等。
使用SelectionDAG进行指令选择的步骤如下:
- 构建初始化 DAG : 该阶段将输入的 LLVM IR code 转换为合法的 SelectionDAG。
- 优化 SelectionDAG:
- 检查 SelectionDAG 中类型的合法性:该阶段会转换/消除一些节点,这些节点对应的类型在目标机器中不支持。
- 优化 SelectionDAG:
- 检查 SelectionDAG 中操作的合法性:该阶段会转换/消除一些节点,这些节点对应的操作在目标机器中不支持。
- 优化 SelectionDAG:
- 指令选择:目标指令选择器会将 DAG 中的操作节点匹配到目标指令。该阶段最终会将与目标无关的输入DAG转换为另一个目标指令DAG。
- 调度和重排:
上面所有步骤完成后,SelectionDAG 会被销毁,然后运行剩下的其他 Pass。
我们可以使用 llc 的部分命令行选型来查看指令选择各个阶段的细节。另外,还可以在 Graphviz 软件的帮助下生成 SelectionDAG 的可视化:
-view-dag-combine1-dags:显示第1步中构建的 初始化DAG。-view-legalize-dags:显示第3步前的 DAG。-view-dag-combine2-dags:显示第3步后的 DAG。-view-isel-dags:显示第7步指令选择前的 DAG。-view-sched-dags:显示第7步指令选择后的 DAG。
上面的命令行选项可能只包含在 Debug 版本的 llc中。
在 指令选择 阶段,其输入是已经进行合法性转换后的 SelectionDAG,然后进行模式匹配,最后输出目标代码的 DAG。以下面的一个代码片段为例:
1 | %t1 = fadd float %W, %X |
上面的 LLVM IR 代码对应的 SelectionDAG 的前缀表示形式:
1 | (fadd:f32 (fmul:f32 (fadd:f32 W, X), Y), Z) |
对于支持 multiply-and-add 的 PowerPC 机器来说,模式匹配后的 DAG 如下所示:
1 | (FMADDS (FADDS W, X), Y, Z) |
其中 FMADDS 在 .td 文件中定义:
1 | def FMADDS : AForm_1<59, 29, |
其中,4-5行代表匹配该指令的模式,其中fadd和fmul在 include/llvm/Target/TargetSelectionDAG.td中定义,F4RC代表寄存器类。llvm-tblgen会根据.td文件生成模式匹配器。
关于 tblgen 更多的信息参看第8节 TableGen 语言。
特别注意的是,SelectionDAG 的节点和选择的指令之间没有一一对应的关系。一个 DAG 节点可能扩展为多个指令,而多个节点也可能合并成一条指令。
对于 IR 中的每个函数,SelectionDAG 类的一个实例由 SelectionDAGBuilder填充。但目标需要一些回调函数来进行降级调用、参数处理、返回跳转等,它为此,必须实现targetlower接口。targetlower 接口的实现提供指令选择过程所需的所有信息,例如:目标上支持哪些数据类型和哪些操作。
在 类型合法化阶段,目标上不支持的类型将被支持的类型替换,例如:如果目标机只支持 32 位范围的整数,那么较小的值将被符号扩展或者零扩展为32位,较大的值会被分隔。vector类型也会做类似的处理。
在 调度和重排 阶段,会将 DAG 进行序列化,也就是说指令需要按照顺序排列。即使在满足数据流和控制流依赖关系的情况下,仍然存在多种排列方案,我们需要选择最能充分利用硬件的顺序。开发者可以将调度模型添加到目标描述文件中(.td文件)。
寄存器分配
TableGen 语言
总述
后端 Pass 需要一种通用的方式获取目标机器的一些属性信息,例如**寄存器分配 Pass **需要知道目标的寄存器类型和数量、指令间约束和寄存器操作符。LLVM 使用一种专门的声明式语言来进行目标描述,这个描述文件将被 tblgen工具进行处理。以 x86 目标为例:
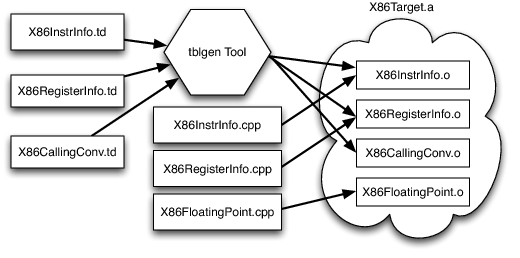
从上图可知,目标描述被 tblgen生成多个源片段,这些源片段可以被其他工具或代码使用。
简单示例(来自 llvm/Target/Target.td):
1 | class Register<string n, list<string> altNames = []> { |
1 | def R0 : Register { |
TableGen 是静态类型的,它必须指定每个值的类型。另外,TableGen工具本身也是模块化的,你可以使用 TableGen库实现自己的TableGen生成器。
在 .td 文件中,类似于 C++,class 描述 了数据的布局结构,def创建了类的一个实例。class之间可以存在继承(包括多种继承)关系,子类会继承父类的所有数据成员,并且可以使用let关键字重写某个数据成员的值。类也可以声明带有模板形参。
一些支持的类型如下:
bit:一个位bits<n>:由 n 位组成的整数类型int:整数值string:字符串list<t>:类型为t的元素列表dag:DAG(在指令选择中使用)class 类:由class声明的类也可以用作类型。
另外,tblgen 支持使用 include包含其他文件,也支持#define、#if和#endif等预处理指令。
顶层描述
寄存器描述
CPU 的体系结构通常会定义一组寄存器,这些寄存器的特性可以有很大的不同。比如有些是通用寄存器、浮点寄存器和向量寄存器,有些可以是特殊寄存器,例如状态寄存器、控制寄存器等。
在具体后端实现中,可以首先定义一个超类,该类继承自Register类;然后为不同类型的寄存器定义子类。注意,所有的寄存器定义都应该放在对应后端的命令空间中(let Namesapce = "<my-backend>")。然后,可以定义寄存器分组,它实例化自RegisterClass类(当然也可以先定义RegisterClass的子类,做一些定制化,再实例化寄存器分组)。最后也可以定义基于寄存器类的操作数,它可以由RegisterOperand<寄存器分组> 类实例化。
指令描述
在指令描述中一般分为定义位编码的类和指令的具体定义类。首先定义一个基类,该基类继承自Instruction类。这个类最重要的字段是 Inst,它保存了指令的编码,其他字段大部分都是对Instruction类的数据成员进行赋值。
定义位编码的类可以有多种类型,它们都定义为上述基类的子类。例如对于 MIPS,它包含R型、L型和J型指令,这三种类型指令的编码是不同的。特别对于跳转指令,由于它是基本块的最后一条指令,需要设置isTerminator=1,另外由于控制流不能通过这条指令,需要设置 isBarrier=1,对于分支指令,也要设置isBranch=1。
调用规则描述
调用规则定义了如何将参数传递给函数以及如果由函数返回值。这些规则包含在 CPU 体系结构的 ABI 规范中。以 MIPS 为例:
1 | def CC_MipsN_VarArg : CallingConv<[ |
其中,在CC_MipsN_VarArg中CCPromoteToType 用于将将小的值提升到 64 位;CCAssignToReg定义了传递参数的寄存器;CCAssignToStack定义了附加参数在栈上分配时的对齐方式。另外,在 RetCC_MipsN 中定义了如何将结果传递给调用函数。
还可以使用 CalleeSavedRegs 类定义被调用函数负责保存的寄存器。
调度模式描述
在调度模式描述中一般会包含和 CPU 相关的底层信息,例如功能单元和流水线级数等。它可以用于指令调度和重排,以获得相对最优的代码顺序。以 MIPS 为例:
1 | def MipsGenericModel : SchedMachineModel { |
其中,IssueWidth定义了同时发射指令的个数,LoadLatency定义了load指令的延迟,MispredictPenalty定义了分支预测失败的代价。
实现 DAG 指令选择类
DAG 指令选择的大部分代码都可以使用tblgen工具生成,但目前仍需要使用手写代码创建类,并将所有内容放在一起。