LLVM 项目介绍
概述
LLVM 是一套开源的编译器基础设施项目, 它包含了一系列模块化的编译器组件和工具链。
参考 《The Architecture of Open Source Applications》 by Chris Lattern.
参考 《Introduction to the LLVM Compiler System》 by Chars Lattern.
为什么需要 LLVM ?
GCC 耦合度太高,其组件很难复用;其他编译器实现之间也同样难以共享代码。
对于 LLVM:
构建高度模块化的编译组件集合 :
- 减少构造一个专用编译器的成本(包括时间成本)
- 组件可以复用和共享
- 允许针对不同的任务选择不同的组件
构建C/C++等主流语言的编译器:
- 更好的编译性能
- 生成更加优化的代码
架构
经典三段式编译器设计:

- 前端:前端主要负责语言的词法、语法和语义分析,并生成 AST 或其他 IR。
- 优化器:将前端输出的 IR 作为输入,对 IR 进行一系列转换来优化代码,包括局部优化和全局优化等。
- 后端:生成目标代码,它主要包括指令选择、寄存器分配和指派、指令调度等过程。
这种架构具有灵活性及可扩展性,当开发一个新语言时,几乎只需要构造一个前端,中间优化器及后端代码生成器则可以复用,如下图所实示:
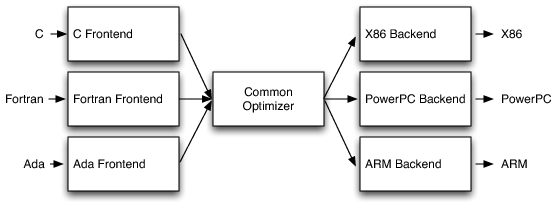
另外,这种架构有利于开源协作和维护,可以更大程度发挥开源社区的作用。
Java 的成功一定程度上得益于该模型,Java的字节码 IR 与具体目标机器解耦,使得 Java 兼容各个平台。解释和运行字节码的 Java 虚拟机则可以作为后端支持各种目标机器和平台。
GCC 的架构也类似于该经典模型,它支持多种语言前端和支持多种后端目标机器。
但不管 Java 还是 GCC 都被设计成单一应用程序(monolithic applications),它们的代码很难被其他应用程序复用。另外,GCC 的代码受分层设计及缺乏抽象的困扰,不同组件间耦合性较强,很难将各个组件单独作为库来使用。
LLVM 三段式设计的实现:
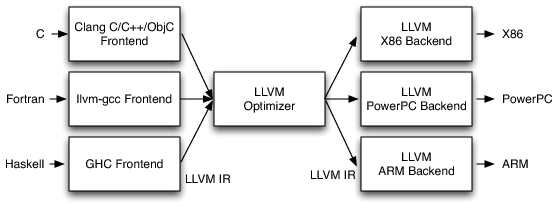
LLVM IR 可以表示为文本格式(因此提高了透明性),而且它是与中间优化器交互的唯一接口。可以说,LLVM IR 是 完备的(Complete) 和 自包含的(self-contained) 。前端生成的LLVM IR 可以通过管道(Pipe)发送给优化器和后续代码生成器。相比而言,GCC 的 GIMPLE 中间表示形式却不是自包含的,它仍然引用源码树的某些信息。
另外重要的是,LLVM 是一系列库的集合,而不是像 GCC 那样的单一命令行编译器,也不是像不透明的 JAVA 或 .NET 虚拟机。LLVM 是基础设施框架,它的一系列非常有用的编译技术可以灵活地被应用于特定的问题。这是它最强大的特性,同时也是最少被理解的设计点。
LLVM 的优化器被组织成一系列 优化 Pass的流水线,这个流水线的任意一个Pass都有机会对 IR 进行更新。不同的优化级别会选择不同种类和数量的优化 Pass。这些 Pass 可以被打包成单个或多个静态库(在Unix环境下的.a文件),库之间尽可能保持松耦合,如果有依赖关系,这些关系信息也会被显式地声明。
这种设计使得特定问题的解决(例如开发图像处理语言的 JIT 编译器)可以灵活的复用上述编译技术。实现者可以根据需求对 Pass 的种类进行取舍或者编写自己的 Pass,因为 LLVM 不是魔法,它不能解决所有的优化问题。
LLVM 的库具有丰富的能力,但它们本身实际上不能做任何事情。这取决于库的用户在开发应用(如 Clang C 编译器)时如何将它们更好地加以利用。这种精心设计的层次性和可分解性是使得 LLVM 优化器在不同的环境中应用到如此多不同的应用的原因。
LLVM IR
LLVM IR 有以下设计目标:
- 轻量级的 runtime 优化
- 跨函数或过程间优化
- 全局优化
- 激进的重构转换
以下面的 C 代码为例:
1 | unsigned add1(unsigned a, unsigned b) { |
转换为 LLVM IR:
1 | define i32 @add1(i32 %a, i32 %b) { |
LLVM IR 是一个底层的 RISC-like 指令集,每个指令为三地址格式。LLVM IR 支持标签,所以它看起来像汇编语言。
另外,它也是 SSA IR 的一种,即它使用无限多的虚拟寄存器,其主要特征是每个变量只赋值一次。SSA 通过简化程序中变量的特性,可以同时达到两种目的:第一,可以简化很多编译优化方法的过程;第二,对很多编译优化方法来说,可以获得更好的优化结果。
更多详细信息参考LLVM 1: IR 汇编语言参考。
LLVM IR 优化
大多数优化遵循一个三段式结构:
- 寻找可以转换的模式(Pattern)
- 对于匹配的实例验证转换是安全和正确的
- 执行转换,更新代码
示例:
1 | %example1 = sub i32 %a, %a |
针对上诉 IR 的优化函数可以如下示:
1 | // X - 0 -> X |
LLVM 代码生成器
和优化器类似,LLVM 的代码生成器也被组织成 Pass 的集合。虽然可以为每种 target都编写专用的代码生成器,但这些生成器实际上都在解决相同的问题。解决这些问题的算法是可以共享的。
代码生成器的 Pass 包括几类:指令选择、寄存器分配、调度、代码布局优化和生成汇编语言等,许多内置的 Pass 被设置为默认执行。代码生成器的作者可以在这些 Pass中进行选择,可以覆盖默认的 Pass 或者完成编写自己特定的 Pass。
LLVM .td 文件
其他详细内容参看 LLVM 2: Backend。